12 Taller de ARIMA
12.1 El caso de consumo de Cemento de la Provincia de Jujuy
Consigna del trabajo:
Revisa el código y en el párrafo senalado con ... Notas ... escribes que es lo que está haciendo el código
... Notas ... library(readr)
cemento <- read_delim("Cemento_Jujuy_Rev1.csv",
";", escape_double = FALSE, trim_ws = TRUE)## Parsed with column specification:
## cols(
## Fecha = col_character(),
## `Real_(Tm)` = col_double(),
## Mes = col_double(),
## Año = col_double()
## )cemento## # A tibble: 120 x 4
## Fecha `Real_(Tm)` Mes Año
## <chr> <dbl> <dbl> <dbl>
## 1 01/01/2007 10239 1 2007
## 2 01/02/2007 9046 2 2007
## 3 01/03/2007 10856 3 2007
## 4 01/04/2007 11376 4 2007
## 5 01/05/2007 11566 5 2007
## 6 01/06/2007 11169 6 2007
## 7 01/07/2007 13619 7 2007
## 8 01/08/2007 12746 8 2007
## 9 01/09/2007 13441 9 2007
## 10 01/10/2007 14121 10 2007
## # … with 110 more rows ... Notas ...Ejemplo:
En este párrafo ya hemos cargamos los datos ... bla, bla ... y utulizamos el comando ts para disponer los datos con la estructura de un objeto ts (tiem series) , esto se puede entender mejor si vemos lo que aparece en la ajuda al tipear ?ts
tsData = ts(cemento$`Real_(Tm)`, start = c(2007,1), frequency = 12)
print(tsData)## Jan Feb Mar Apr May Jun Jul
## 2007 10239 9046 10856 11376 11566 11169 13619
## 2008 10571 9256 9243 12462 12641 12804 13594
## 2009 12392 9352 10295 11825 10349 13353 15105
## 2010 11316 9517 13181 12936 10322 12321 12260
## 2011 11496 10393 11005 13188 12979 13201 13656
## 2012 24882 9676 13870 10184 13814 14139 14325
## 2013 13206 11124 13795 15845 16767 15702 18306
## 2014 16360 12823 13694 15278 16551 14963 15866
## 2015 15959 13611 14388 18788 18128 19910 20633
## 2016 15514 13730 14364 17178 14523 15277 15858
## Aug Sep Oct Nov Dec
## 2007 12746 13441 14121 13887 11171
## 2008 13138 14140 13741 11459 10526
## 2009 13626 13968 15156 13095 13034
## 2010 11941 13102 14377 13968 13980
## 2011 13069 16376 15529 17588 13747
## 2012 14670 13964 16903 13990 13314
## 2013 17289 18257 19841 18277 16107
## 2014 15824 18078 19915 20225 16540
## 2015 21185 24826 25553 20142 19540
## 2016 18546 16276 17035 15137 16146plot(tsData)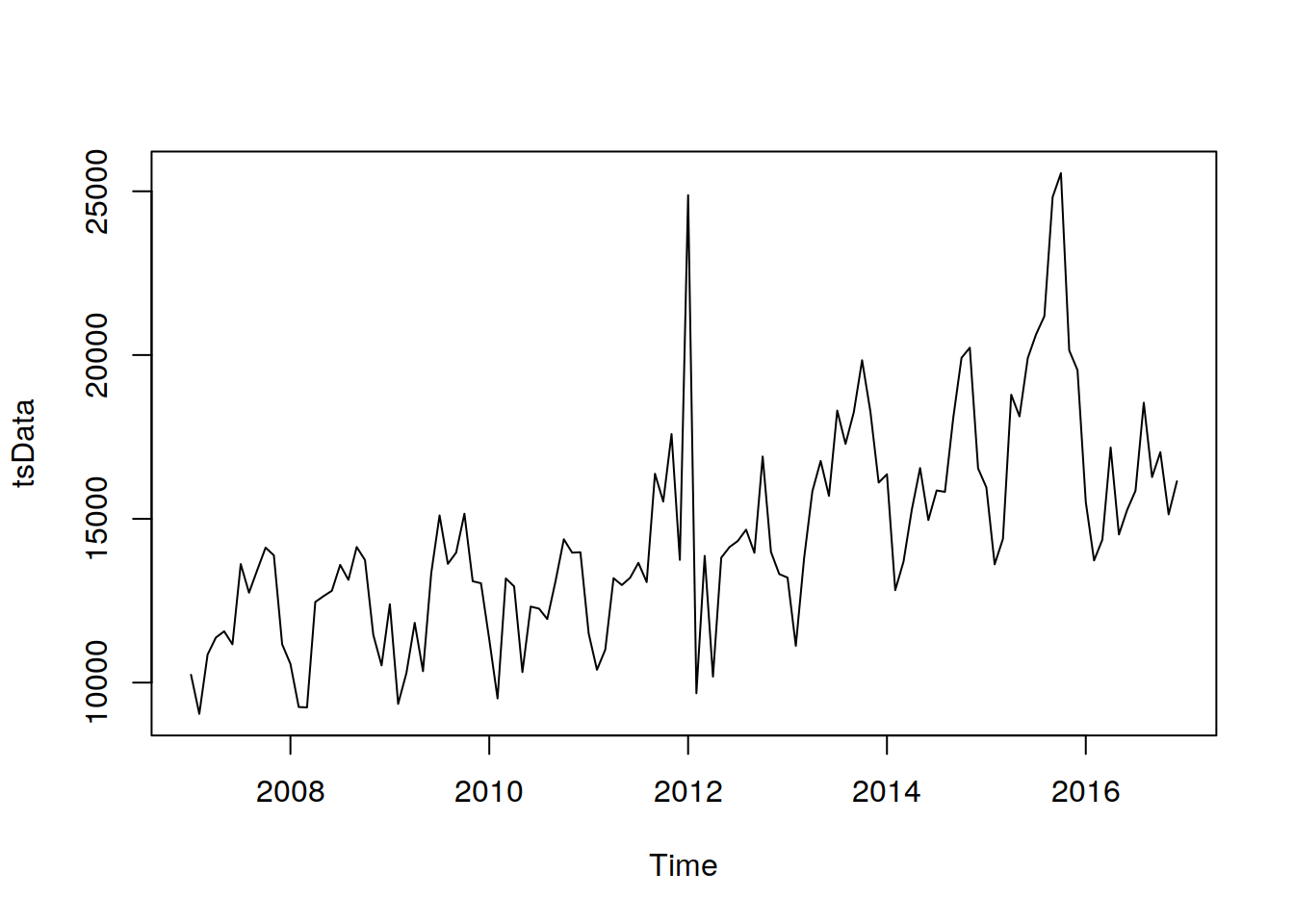
... Notas ...
componentes.ts = decompose(tsData)
plot(componentes.ts)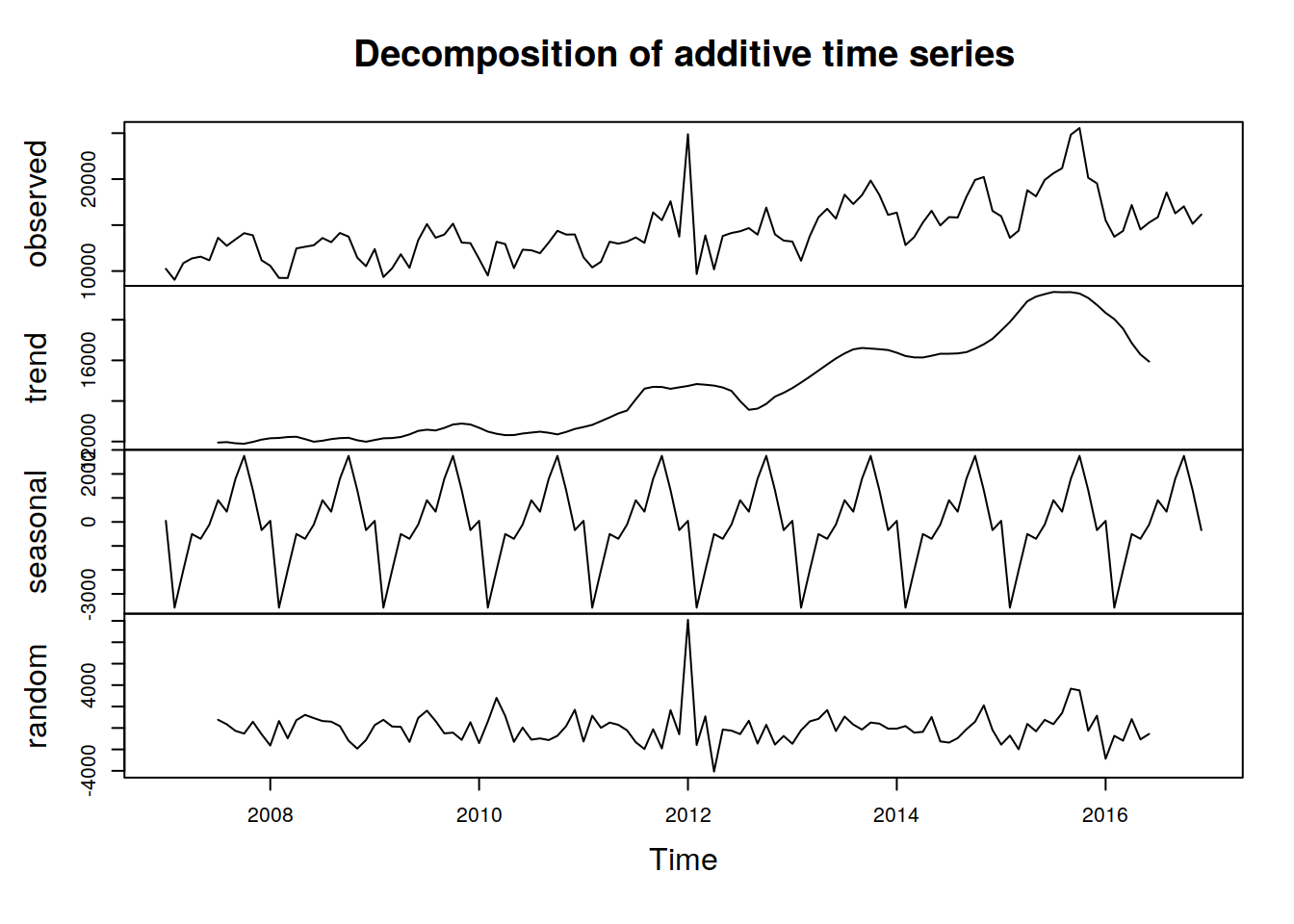
12.2 Test de Phillips-Perron (KPSS Unit Root Test)
Ver más detalles en el paper de [@PHILLIPS2002239]
para que estas referencia funcionen debemos agragar al preámbulo el comando * bibliography: bibliografia.bib * y tener un archivo en la misma carpeta del Rmd que tenga las referencias en formato bib.
En estadística y econometría, la prueba de Phillips-Perron (el nombre viene de Peter Phillips y CB Pierre Perron), es una prueba de raíz unitaria. Es decir, se utiliza en el análisis de series de tiempo para probar la hipótesis nula de que una serie de tiempo es integrada de orden 1. Se basa en la prueba de Dickey-Fuller de que la hipótesis nula es \(\rho = 0\) en \(y_{t}=\rho y_{t-1}+u_{t}\) , donde \(\Delta\) es la primera diferencia del operador. Al igual que la prueba de Dickey-Fuller aumentada, la prueba de Phillips-Perron aborda la cuestión de que el proceso de generación de datos para \(y_{t}\) podría tener un orden superior de autocorrelación que es admitido en la ecuación de prueba - haciendo \(y_{t-1}\) endógeno e invalidando así el Dickey-Fuller t-test . Mientras que la prueba de Dickey-Fuller aumentada aborda esta cuestión mediante la introducción de retardos de \(\Delta y_{t}\) como variables independientes en la ecuación de la prueba, la prueba de Phillips-Perron hace un no-paramétricos corrección a la estadística t-test. El ensayo es robusto con respecto a no especificado autocorrelación y heterocedasticidad en el proceso de alteración de la ecuación de prueba.
El artículo de Davidson y MacKinnon(2004) muestra que la prueba de Phillips-Perron es menos eficiente en muestras finitas que la prueba de Dickey-Fuller aumentada.2.
#install.packages("fUnitRoots")
library("fUnitRoots")
urkpssTest(tsData, type = c("tau"), lags = c("short"),use.lag = NULL, doplot = TRUE)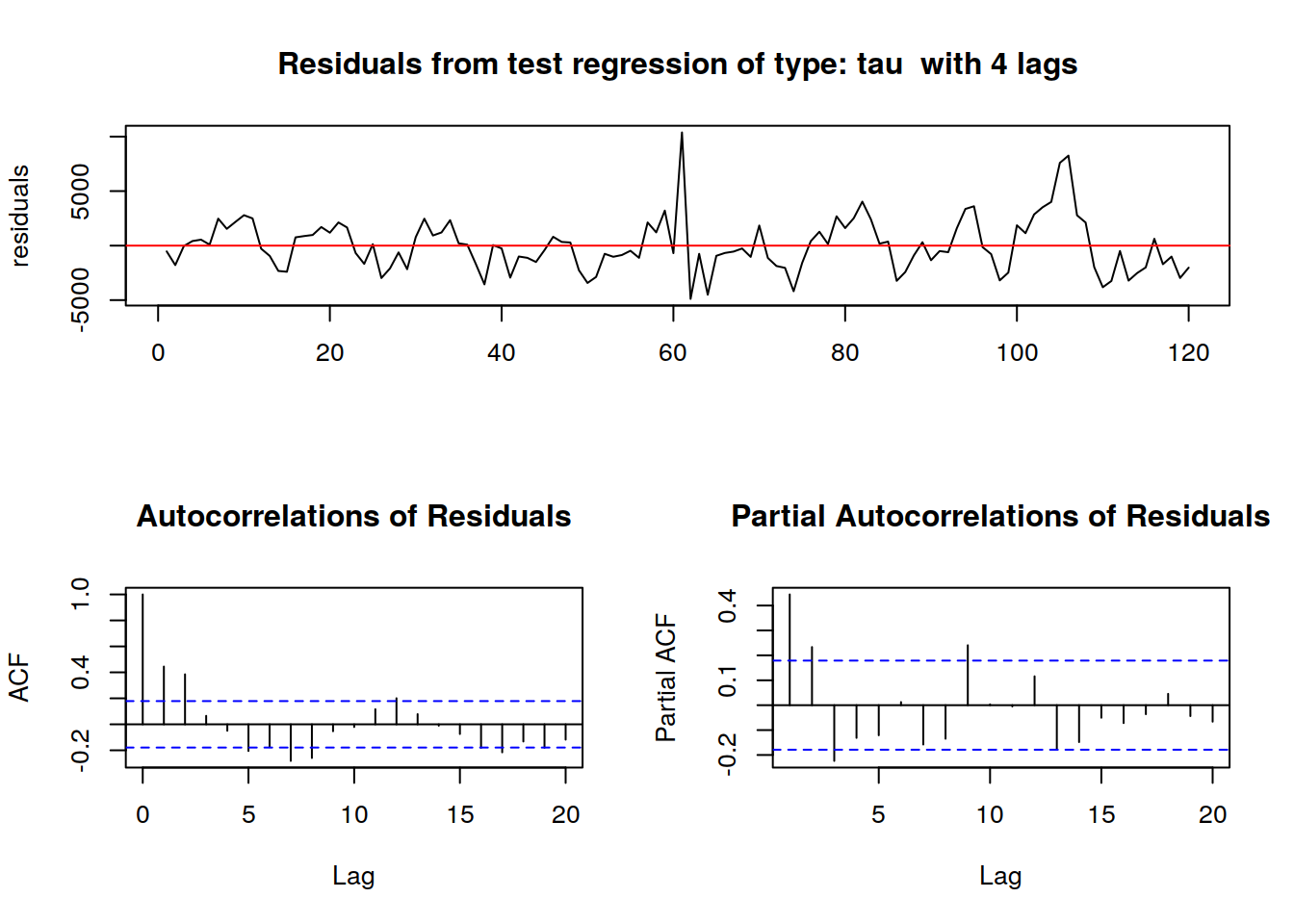
##
## Title:
## KPSS Unit Root Test
##
## Test Results:
## NA
##
## Description:
## Thu Nov 5 13:25:37 2020 by user:tsstationary = diff(tsData, differences=1)
plot(tsstationary)
... Nota ... Este método es muy usado en el trabajo de : [@CHENG2021120398]
acf(tsData,lag.max=140)
Otro trabajo para consultar en este caso: [@HONDROYIANNIS2002319]
timeseriesseasonallyadjusted <- tsData-componentes.ts$seasonal
tsstationary <- diff(timeseriesseasonallyadjusted, differences=1)plot(tsstationary)
fitARIMA <- arima(tsData, order=c(1,1,1),seasonal =list(order = c(1,0,0), period = 12),method="ML")
#install.packages("lmtest")
library(lmtest)
coeftest(fitARIMA)##
## z test of coefficients:
##
## Estimate Std. Error z value Pr(>|z|)
## ar1 -0.636445 0.149663 -4.2525 2.114e-05 ***
## ma1 0.158531 0.201051 0.7885 0.4304
## sar1 0.342447 0.087751 3.9025 9.520e-05 ***
## ---
## Signif. codes:
## 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1#install.packages("forecast")
library(forecast)
auto.arima(tsData, trace=TRUE)##
## ARIMA(2,1,2)(1,0,1)[12] with drift : Inf
## ARIMA(0,1,0) with drift : 2209.626
## ARIMA(1,1,0)(1,0,0)[12] with drift : 2173.219
## ARIMA(0,1,1)(0,0,1)[12] with drift : 2182.648
## ARIMA(0,1,0) : 2207.602
## ARIMA(1,1,0) with drift : 2184.66
## ARIMA(1,1,0)(2,0,0)[12] with drift : 2170.225
## ARIMA(1,1,0)(2,0,1)[12] with drift : Inf
## ARIMA(1,1,0)(1,0,1)[12] with drift : Inf
## ARIMA(0,1,0)(2,0,0)[12] with drift : 2206.058
## ARIMA(2,1,0)(2,0,0)[12] with drift : Inf
## ARIMA(1,1,1)(2,0,0)[12] with drift : 2172.043
## ARIMA(0,1,1)(2,0,0)[12] with drift : 2174.54
## ARIMA(2,1,1)(2,0,0)[12] with drift : Inf
## ARIMA(1,1,0)(2,0,0)[12] : 2168.058
## ARIMA(1,1,0)(1,0,0)[12] : 2171.104
## ARIMA(1,1,0)(2,0,1)[12] : Inf
## ARIMA(1,1,0)(1,0,1)[12] : Inf
## ARIMA(0,1,0)(2,0,0)[12] : 2203.933
## ARIMA(2,1,0)(2,0,0)[12] : 2170.056
## ARIMA(1,1,1)(2,0,0)[12] : 2169.838
## ARIMA(0,1,1)(2,0,0)[12] : 2172.375
## ARIMA(2,1,1)(2,0,0)[12] : 2162.33
## ARIMA(2,1,1)(1,0,0)[12] : 2174.584
## ARIMA(2,1,1)(2,0,1)[12] : Inf
## ARIMA(2,1,1)(1,0,1)[12] : Inf
## ARIMA(3,1,1)(2,0,0)[12] : 2160.637
## ARIMA(3,1,1)(1,0,0)[12] : 2164.965
## ARIMA(3,1,1)(2,0,1)[12] : Inf
## ARIMA(3,1,1)(1,0,1)[12] : Inf
## ARIMA(3,1,0)(2,0,0)[12] : 2168.491
## ARIMA(4,1,1)(2,0,0)[12] : 2162.877
## ARIMA(3,1,2)(2,0,0)[12] : 2162.877
## ARIMA(2,1,2)(2,0,0)[12] : 2161.094
## ARIMA(4,1,0)(2,0,0)[12] : 2169.059
## ARIMA(4,1,2)(2,0,0)[12] : Inf
## ARIMA(3,1,1)(2,0,0)[12] with drift : Inf
##
## Best model: ARIMA(3,1,1)(2,0,0)[12]## Series: tsData
## ARIMA(3,1,1)(2,0,0)[12]
##
## Coefficients:
## ar1 ar2 ar3 ma1 sar1
## 0.3294 0.3832 -0.1890 -0.9441 0.2381
## s.e. 0.0961 0.0941 0.0934 0.0368 0.0913
## sar2
## 0.2564
## s.e. 0.0980
##
## sigma^2 estimated as 4039147: log likelihood=-1072.81
## AIC=2159.63 AICc=2160.64 BIC=2179.08fitARIMA <- arima(tsData, order=c(3,1,1),seasonal =list(order = c(2,0,0), period = 12),method="ML")futurVal <- forecast(fitARIMA,h=24, level=c(82.5))
plot(futurVal)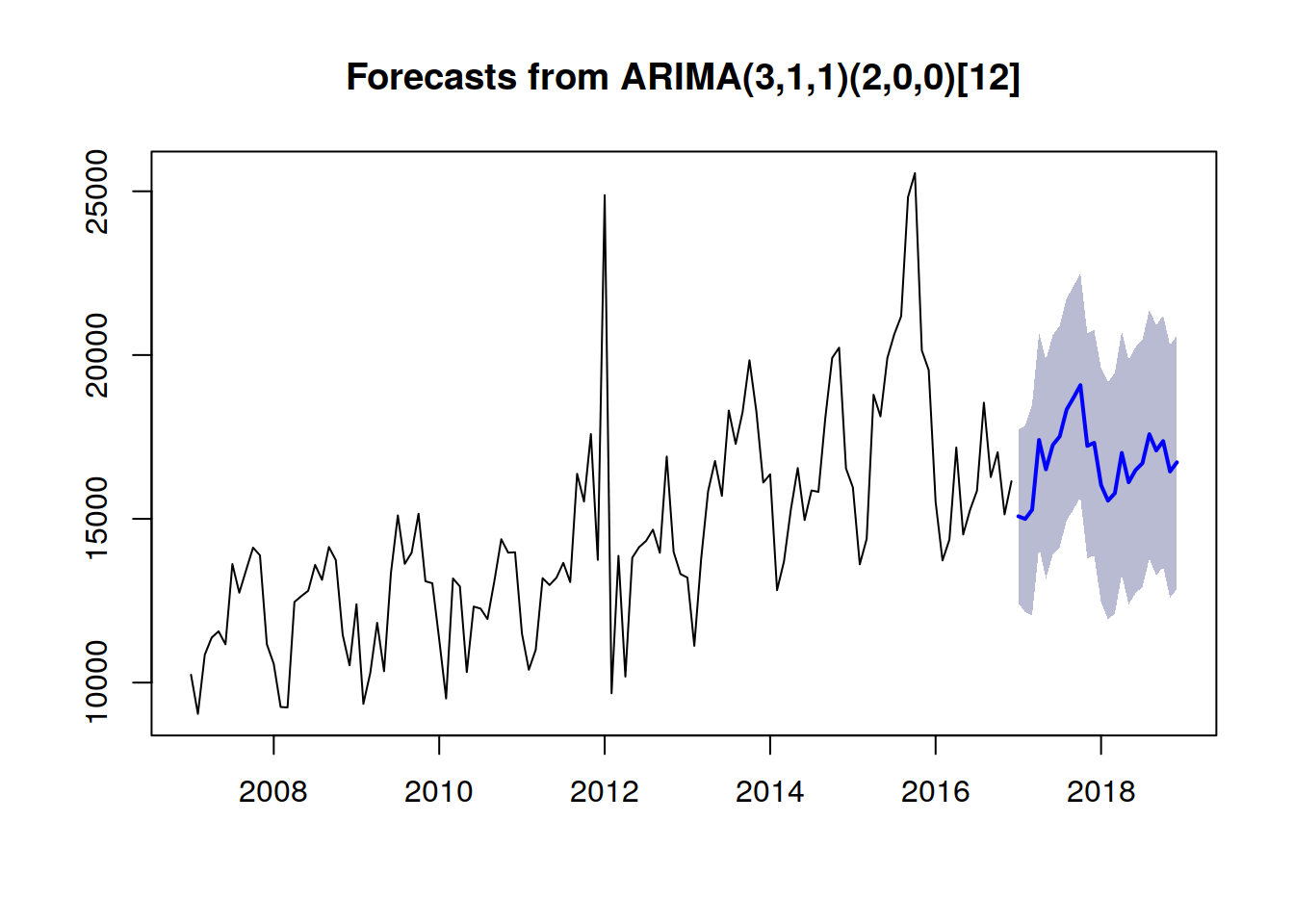
12.3 Obtener el precio de las acciones.
Para obtener el precio de las acciones (stock) en necesario conocer su título. Por ejemplo AMZN es el indicativo de las acciones de Amazon.com. Se necesitan varias bibliotecas para acceder al precio de la acción, sí como de los inventarios y activos.
library(quantmod)## Loading required package: xts##
## Attaching package: 'xts'## The following objects are masked from 'package:dplyr':
##
## first, last## Loading required package: TTR##
## Attaching package: 'TTR'## The following object is masked from 'package:fBasics':
##
## volatility## Version 0.4-0 included new data defaults. See ?getSymbols.library(xts)
library(rvest)## Loading required package: xml2##
## Attaching package: 'rvest'## The following object is masked from 'package:readr':
##
## guess_encodinglibrary(tidyverse)## ── Attaching packages ───────── tidyverse 1.2.1 ──## ✔ tibble 2.1.3 ✔ purrr 0.3.4
## ✔ tidyr 1.0.2 ✔ stringr 1.4.0
## ✔ tibble 2.1.3 ✔ forcats 0.4.0## ── Conflicts ──────────── tidyverse_conflicts() ──
## ✖ ggplot2::%+%() masks psych::%+%()
## ✖ ggplot2::alpha() masks psych::alpha()
## ✖ dplyr::arrange() masks plyr::arrange()
## ✖ stringr::boundary() masks strucchange::boundary()
## ✖ purrr::compact() masks plyr::compact()
## ✖ dplyr::compute() masks neuralnet::compute()
## ✖ dplyr::count() masks plyr::count()
## ✖ dplyr::failwith() masks plyr::failwith()
## ✖ dplyr::filter() masks timeSeries::filter(), stats::filter()
## ✖ xts::first() masks dplyr::first()
## ✖ dplyr::group_rows() masks kableExtra::group_rows()
## ✖ rvest::guess_encoding() masks readr::guess_encoding()
## ✖ dplyr::id() masks plyr::id()
## ✖ dplyr::lag() masks timeSeries::lag(), stats::lag()
## ✖ xts::last() masks dplyr::last()
## ✖ dplyr::mutate() masks plyr::mutate()
## ✖ purrr::pluck() masks rvest::pluck()
## ✖ dplyr::recode() masks car::recode()
## ✖ dplyr::rename() masks plyr::rename()
## ✖ purrr::some() masks car::some()
## ✖ dplyr::summarise() masks plyr::summarise()
## ✖ dplyr::summarize() masks plyr::summarize()library(stringr)
library(forcats)
library(lubridate)##
## Attaching package: 'lubridate'## The following objects are masked from 'package:dplyr':
##
## intersect, setdiff, union## The following objects are masked from 'package:base':
##
## date, intersect, setdiff, unionlibrary(plotly)##
## Attaching package: 'plotly'## The following object is masked from 'package:ggplot2':
##
## last_plot## The following object is masked from 'package:timeSeries':
##
## filter## The following objects are masked from 'package:plyr':
##
## arrange, mutate, rename, summarise## The following object is masked from 'package:stats':
##
## filter## The following object is masked from 'package:graphics':
##
## layoutlibrary(dplyr)
library(PerformanceAnalytics)##
## Attaching package: 'PerformanceAnalytics'## The following objects are masked from 'package:timeDate':
##
## kurtosis, skewness## The following object is masked from 'package:graphics':
##
## legendgetSymbols("AMZN",from="2008-08-01",to="2018-08-17")## 'getSymbols' currently uses auto.assign=TRUE by default, but will
## use auto.assign=FALSE in 0.5-0. You will still be able to use
## 'loadSymbols' to automatically load data. getOption("getSymbols.env")
## and getOption("getSymbols.auto.assign") will still be checked for
## alternate defaults.
##
## This message is shown once per session and may be disabled by setting
## options("getSymbols.warning4.0"=FALSE). See ?getSymbols for details.## [1] "AMZN"AMZN_log_returns<-AMZN%>%Ad()%>%dailyReturn(type='log')Hemos obtenido las cotizaciones desde Agosto del 2008 hasta el 17 de Agosto de 2018.
Procederemos a realizar un análisis técnico de la cotización.
El primer gráfico de la serie de gráficos es sencillo, ya que muestra el gráfico de precios de Amazon:
AMZN%>%Ad()%>%chartSeries()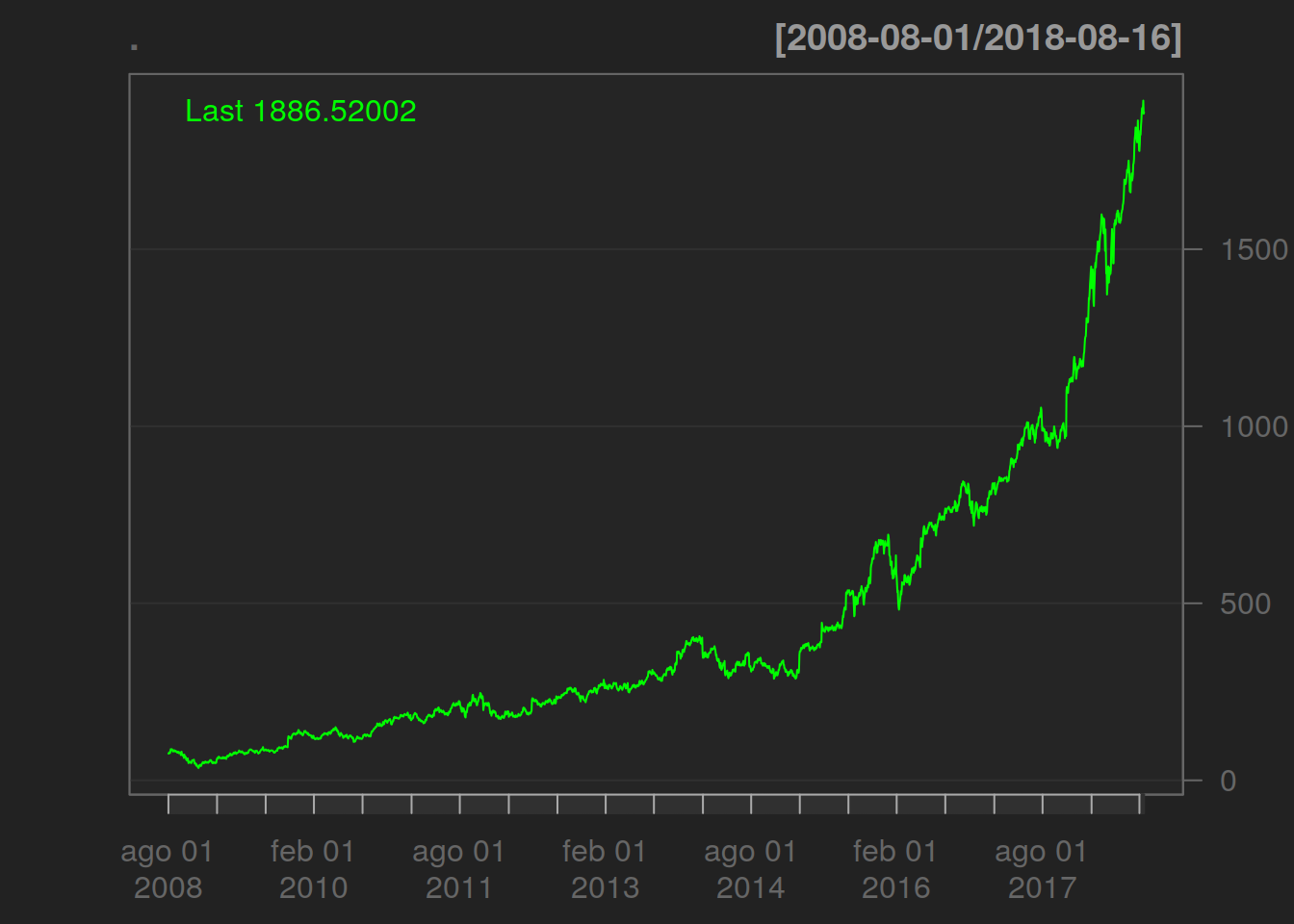
La segunda serie de gráficos muestra el gráfico de la banda de Bollinger, el % de cambio de Bollinger, el volumen negociado y la divergencia de convergencia de la media móvil solo en 2018:
AMZN%>%chartSeries(TA='addBBands();addVo();addMACD()',subset='2018')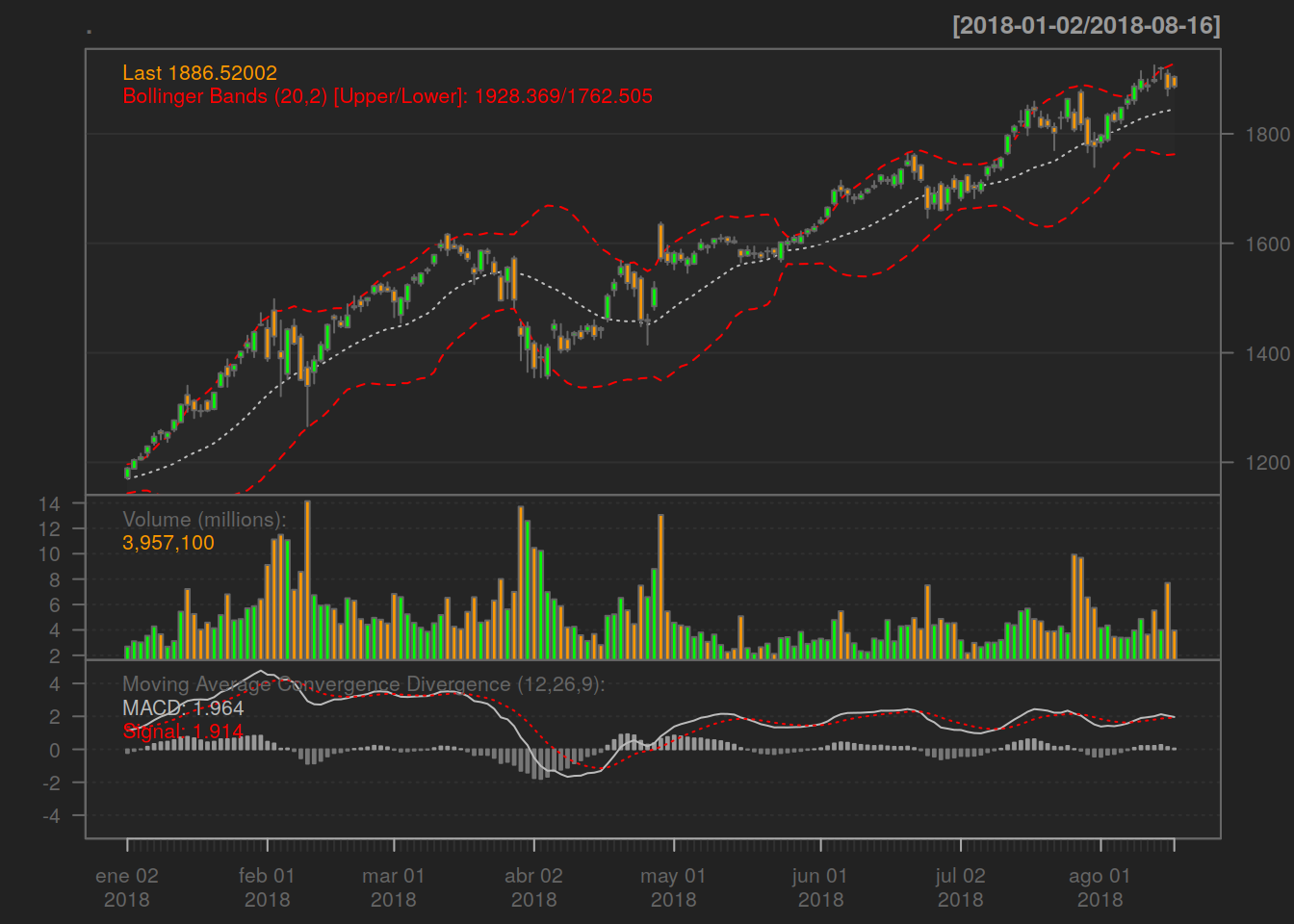
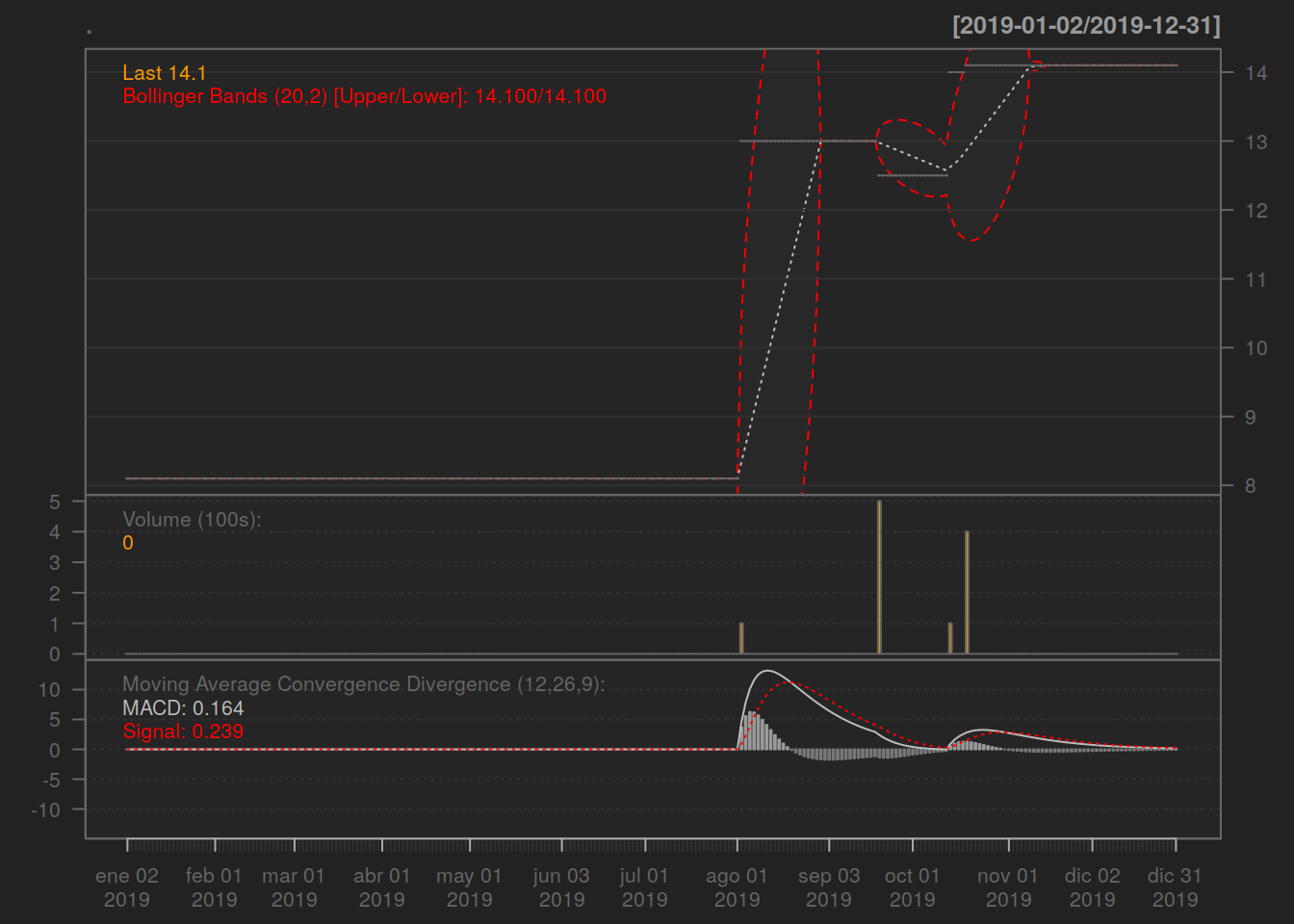
La media móvil es importante para comprender los gráficos técnicos de Amazon (AMZN). Suaviza las fluctuaciones diarias de los precios al promediar los precios de las acciones y es eficaz para identificar tendencias potenciales.
El gráfico de la Banda de Bollinger traza dos desviaciones estándar de la media móvil y se utiliza para medir la volatilidad de la acción. El gráfico de volumen muestra cómo se negocian sus acciones a diario. La divergencia de convergencia de la media móvil da a los analistas técnicos señales de compra / venta. La regla general es: si cae por debajo de la línea, es hora de vender. Si se eleva por encima de la línea, está experimentando un impulso ascendente.
Los gráficos anteriores se utilizan generalmente para decidir si comprar o vender una acción. Como regla general si en la bolsa se están vendiendo las acciones de tu empresa, como gerente de producción tu misión es incrementar el inventario de producto terminado y/o solicitar crédito de materia prima a tu proveedor y bajar el inventario de productos semi-elaborados.
12.4 Ejercicio de la cotización de HOLCIM Argentina
Obtenemos la evolución de los precios
getSymbols("HARG.BA",from="2008-08-01",to="2020-10-17")## Warning: HARG.BA contains missing values. Some
## functions will not work if objects contain missing
## values in the middle of the series. Consider using
## na.omit(), na.approx(), na.fill(), etc to remove
## or replace them.## [1] "HARG.BA"HARG.BA_log_returns<-HARG.BA%>%Ad()%>%dailyReturn(type='log')## Warning in to_period(xx, period =
## on.opts[[period]], ...): missing values removed
## from data12.4.1 Gráfica de Precios
HARG.BA%>%Ad()%>%chartSeries()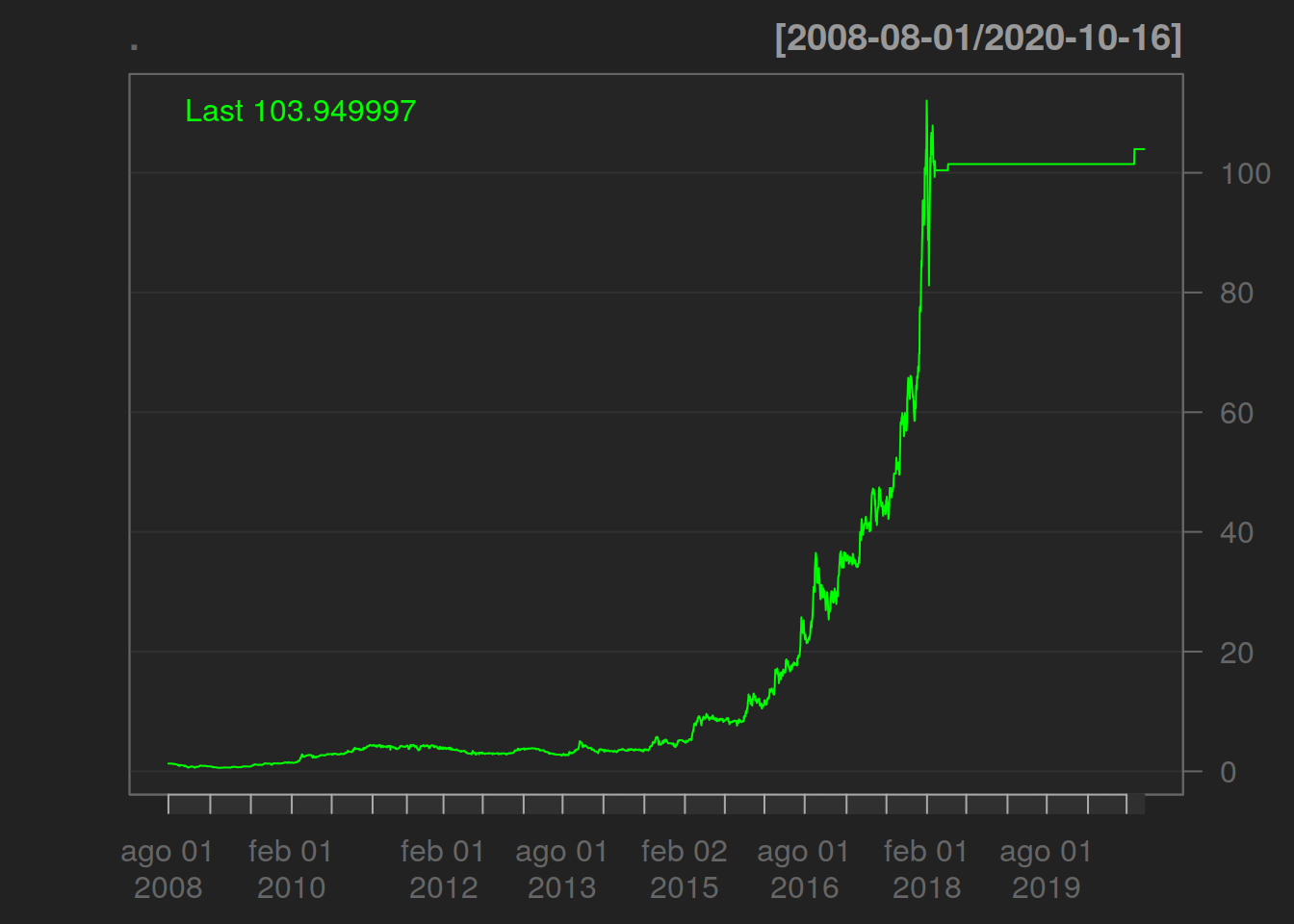
12.4.2 Gráfica de Volatilidad
HARG.BA%>%chartSeries(TA='addBBands();addVo();addMACD()',subset='2015')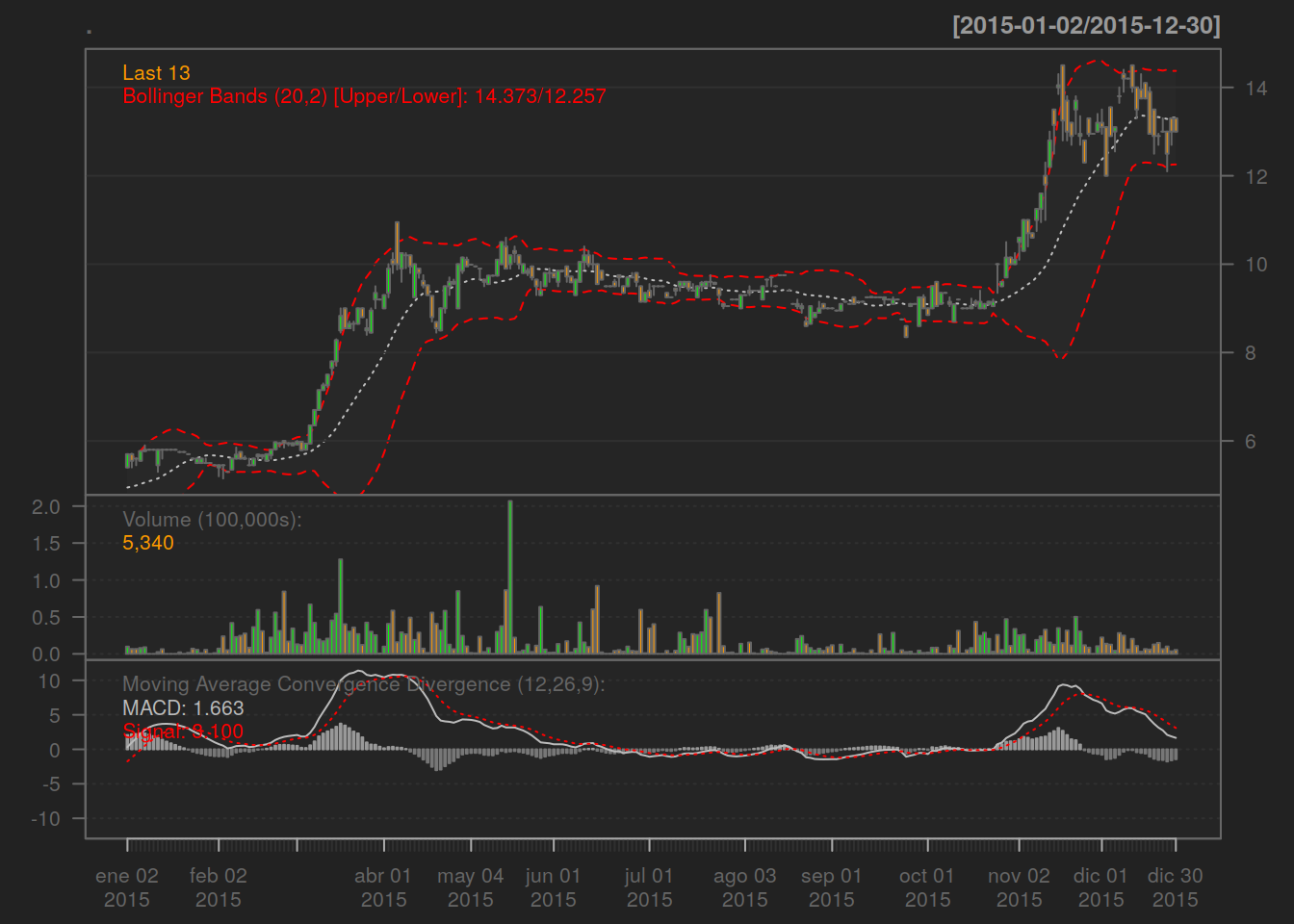
Realizaremos una comparación con Holcim Filipinas
getSymbols("HCPHY",from="2008-08-01",to="2020-10-17")## Warning: HCPHY contains missing values. Some
## functions will not work if objects contain missing
## values in the middle of the series. Consider using
## na.omit(), na.approx(), na.fill(), etc to remove
## or replace them.## [1] "HCPHY"HCPHY_log_returns<-HCPHY%>%Ad()%>%dailyReturn(type='log')## Warning in to_period(xx, period =
## on.opts[[period]], ...): missing values removed
## from data12.4.3 Gráfica de Precios
HCPHY%>%Ad()%>%chartSeries()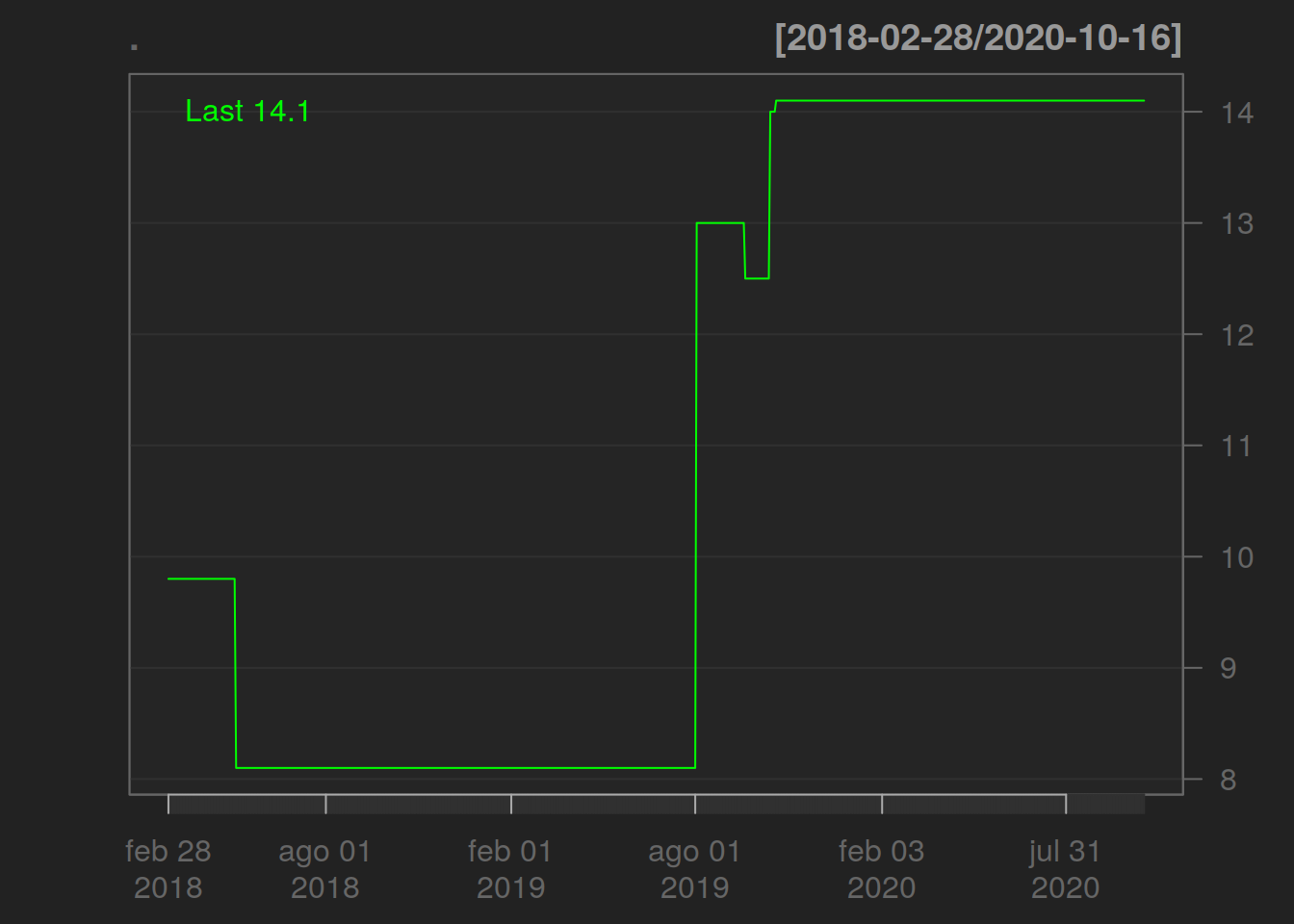
12.4.4 Gráfica de Volatilidad
HCPHY%>%chartSeries(TA='addBBands();addVo();addMACD()',subset='2019')