13 Minería de Texto
13.1 Análisis de Sentimiento
13.1.1 Politica Industrial, Desarrollo e Innovación
Las redes sociales se han convertico en la arena en la que todos podemos ver los resultados de nuestras hipotesis, sean formuladas por quien quiera de los sectores que constituyen el modelo de triple hélice.
Pólitica, entendida como una decisión tomada por anticipado es un forma de indagar las causas que provocan nuestro llanto o nuestra alegría
En momento de elecciones es vital ver cual es la visión de nuestros candidatos sobre el desarrollo y como utilizarán la innovación para llegar a ello
En este trabajo exploraremos una técnica que nos perimte compararnos con otros países y otras regiones respecto a la visión y destino que nuestros sistemas productivos locales ejercerán en nuestro futuro.
13.1.2 Análisis de Sentimiento con R
En este documento revisaremos cómo realizar análisis de sentimientos usando R y el léxico Afinn.
Nos enfocaremos en algunas de las opciones que tenemos para analizar sentimientos usando R más que en los resultados específicos de los datos que usaremos, pero en el proceso veremos maneras para contestar ciertas preguntas:
No es importnte lo que veamos, lo que importa es entender como podemos tomar una montaña de datos de un corpus que puede ser desde el cuerpo legal, reglamentos, decretos etc. vinculados a la politica industrial o artículos científicos, o propuestas del tipo que imaginemos para apoyar o descartar las hipotesis de trabajo de damos por ciertas.
13.1.3 Preguntas
Si hacemos una encuesta libre con los actores de una cámara industrial, un cluster o un sector representativo podemos armar un corpus con el que podremos inferir respuestas a ciertas cuestiones vitales y que sentimiento tienen los actores en torno a esos conceptos.
- ¿Cuáles palabras han influido para determinar los sentimientos?
- ¿Qué sentimientos han sido predominantes? ¿Positivos, negativos?
- ¿Cómo han cambiado los sentimientos a través del tiempo?
- Como datos usaremos la actividad de Twitter de los candidatos a la presidencia de Freedonia durante el 2018, hasta el 11 de Abril. Pero antes, preparemos nuestro entorno de trabajo.
13.1.4 Preparación
Los paquetes más importantes que usaremos son tidyverse, que nos permite importar multiples paquetes que nos facilitarán el análisis y manipulación de datos, y tidytext, que contiene las herramientas para manipular texto. Además usaremos tm contiene herramientas de mineria de textos, lubridate para fechas de manera consistente, y zoo y scales que contienen funciones para realizar tareas comunes de análisis y presentación de datos. Si no cuentas con estos paquetes, puedes obtenerlos usando la función install.packages()
13.1.5 Comando para instalar bibliotecas
Recuerda instalarlas antes de invocarlas
library(tidyverse)
library(tidytext)
library(tm)
library(lubridate)
library(zoo)
library(scales)library(tidyverse)
library(tidytext)
library(tm)## Loading required package: NLP##
## Attaching package: 'NLP'## The following object is masked from 'package:ggplot2':
##
## annotatelibrary(lubridate)
library(zoo)
library(scales)##
## Attaching package: 'scales'## The following object is masked from 'package:purrr':
##
## discard## The following object is masked from 'package:readr':
##
## col_factor## The following objects are masked from 'package:psych':
##
## alpha, rescale13.1.6 Visualización
Definimos un tema (hoja de estilos)para facilitar la visualización de nuestros resultados.
tema_graf <-
theme_minimal() +
theme(text = element_text(family = "serif"),
panel.grid.minor = element_blank(),
strip.background = element_rect(fill = "#EBEBEB", colour = NA),
legend.position = "none", legend.box.background = element_rect(fill = "#EBEBEB", colour = NA))13.1.7 Importando los datos
Descargamos los datos con los tuits de los candidatos a la presidencia desde la siguiente dirección, estos han sido obtenidos usando la API de Twitter.
https://raw.githubusercontent.com/jboscomendoza/rpubs/master/sentimientos_afinn/tuits_candidatos.csvdownload.file("https://raw.githubusercontent.com/jboscomendoza/rpubs/master/sentimientos_afinn/tuits_candidatos.csv",
"tuits_candidatos.csv")13.1.8 Cargas datos en memoria
Leemos los tuits usando read.csv(). El argumento fileEncoding = "latin1" es importante para mostrar correctamente las vocales con tildes, la ñ y otro caracteres especiales.
tuits <- read.csv("tuits_candidatos.csv", stringsAsFactors = F, fileEncoding = "latin1") %>%
tbl_df()13.1.9 Nuestros datos lucen así:
tuits## # A tibble: 2,660 x 4
## status_id created_at screen_name text
## <dbl> <fct> <fct> <fct>
## 1 7.30e17 09/05/2016 … lopezobrad… Proceso hab…
## 2 7.30e17 10/05/2016 … lopezobrad… "MORENA lle…
## 3 7.30e17 10/05/2016 … lopezobrad… Muchas feli…
## 4 7.31e17 12/05/2016 … lopezobrad… "En Chihuah…
## 5 7.31e17 13/05/2016 … lopezobrad… Están desat…
## 6 7.31e17 13/05/2016 … lopezobrad… No sé a ust…
## 7 7.32e17 15/05/2016 … lopezobrad… Luego de la…
## 8 7.32e17 16/05/2016 … lopezobrad… Hoy 15 de m…
## 9 7.32e17 17/05/2016 … lopezobrad… "El periódi…
## 10 7.33e17 18/05/2016 … lopezobrad… Sandra Ávil…
## # … with 2,650 more rowsPara este análisis de sentimiento usaremos el léxico Afinn. Este es un conjunto de palabras, puntuadas de acuerdo a qué tan positivamente o negativamente son percibidas. Las palabras que son percibidas de manera positiva tienen puntuaciones de -4 a -1; y las positivas de 1 a 4.
La versión que usaremos es una traducción automática, de inglés a español, de la versión del léxico presente en el conjunto de datos sentiments de tidytext, con algunas correcciones manuales. Por supuesto, esto quiere decir que este léxico tendrá algunos defectos, pero será suficiente para nuestro análisis.
13.1.10 Descargamos este léxico de la siguiente dirección:
https://raw.githubusercontent.com/jboscomendoza/rpubs/master/sentimientos_afinn/lexico_afinn.en.es.csvdownload.file("https://raw.githubusercontent.com/jboscomendoza/rpubs/master/sentimientos_afinn/lexico_afinn.en.es.csv",
"lexico_afinn.en.es.csv")13.1.11 Aplicación del léxico
De nuevo usamos la función read.csv() para importar los datos.
afinn <- read.csv("lexico_afinn.en.es.csv", stringsAsFactors = F, fileEncoding = "latin1") %>%
tbl_df()13.1.12 Este léxico luce así:
afinn## # A tibble: 2,476 x 3
## Palabra Puntuacion Word
## <fct> <int> <fct>
## 1 a bordo 1 aboard
## 2 abandona -2 abandons
## 3 abandonado -2 abandoned
## 4 abandonar -2 abandon
## 5 abatido -2 dejected
## 6 abatido -3 despondent
## 7 aborrece -3 abhors
## 8 aborrecer -3 abhor
## 9 aborrecible -3 abhorrent
## 10 aborrecido -3 abhorred
## # … with 2,466 more rowsTenemos tres columnas. Una con palabras en español, su puntuación y una tercera columna con la misma palabra, en inglés.
Hora de preparar nuestros datos para análisis.
13.2 Preparación preliminar de datos capturados
Fechas
Lo primero que necesitamos es filtrar el objeto tuits para limitar nuestros datos sólo a los del 2018. Manipulamos la columna created_at con la función separate() de tidyr. Separamos esta columna en una fecha y hora del día, y después separaremos la fecha en día, mes y año. Usamos la función ymd() de lubridate para convertir la nueva columna Fecha a tipo de dato fecha.
Por último, usamos filter() de dplyr para seleccionar sólo los tuits hechos en el 2018.
tuits <-
tuits %>%
separate(created_at, into = c("Fecha", "Hora"), sep = " ") %>%
separate(Fecha, into = c("Dia", "Mes", "Periodo"), sep = "/",
remove = FALSE) %>%
mutate(Fecha = dmy(Fecha),
Semana = week(Fecha) %>% as.factor(),
text = tolower(text)) %>%
filter(Periodo == 2018)13.2.1 Convirtiendo tuits en palabras
Necesitamos separar cada tuit en palabras, para así asignarle a cada palabra relevante una puntuación de sentimiento usando el léxico Afinn. Usamos la función unnest_token() de tidytext, que tomara los tuits en la columna text y los separá en una nueva columna llamada Palabra Hecho esto, usamos left_join() de dplyr, para unir los objetos tuits y afinn, a partir del contenido de la columna Palabra. De este modo, obtendremos un data frame que contiene sólo los tuits con palabras presentes en el léxico Afinn.
Además, aprovechamos para crear una columna con mutate() de dplyr a las palabras como Positiva o Negativa. Llamaremos esta columna Tipo y cambiamos el nombre de la columna screen_name a Candidato.
13.2.2 Analítica Lexográfica
tuits_afinn <-
tuits %>%
unnest_tokens(input = "text", output = "Palabra") %>%
inner_join(afinn, ., by = "Palabra") %>%
mutate(Tipo = ifelse(Puntuacion > 0, "Positiva", "Negativa")) %>%
rename("Candidato" = screen_name)## Warning: Column `Palabra` joining factor and
## character vector, coercing into character vectorObtenemos también una puntuación por tuit, usando group_by() y summarise() de dplyr, y la agregamos tuits para usarla después. Tambien asignamos a los tuits sin puntuación positiva o negativa un valor de 0, que indica neutralidad. Por último cambiamos el nombre de la columna screen_name a Candidato
13.2.3 Cambio Columna
tuits <-
tuits_afinn %>%
group_by(status_id) %>%
summarise(Puntuacion_tuit = mean(Puntuacion)) %>%
left_join(tuits, ., by = "status_id") %>%
mutate(Puntuacion_tuit = ifelse(is.na(Puntuacion_tuit), 0, Puntuacion_tuit)) %>%
rename("Candidato" = screen_name)13.3 Exploración
Con esto estamos listos para empezar.
Explorando los datos, medias por día Empecemos revisando cuántas palabras en total y cuantas palabras únicas ha usado cada candidato con count(), group_by() y distinct() de dplyr.
13.3.1 Palabras Totales
# Total
tuits_afinn %>%
count(Candidato)## # A tibble: 5 x 2
## Candidato n
## <fct> <int>
## 1 JaimeRdzNL 525
## 2 JoseAMeadeK 533
## 3 lopezobrador_ 183
## 4 Mzavalagc 838
## 5 RicardoAnayaC 61713.3.2 Palabras Únicas
# Únicas
tuits_afinn %>%
group_by(Candidato) %>%
distinct(Palabra) %>%
count()## # A tibble: 5 x 2
## # Groups: Candidato [5]
## Candidato n
## <fct> <int>
## 1 JaimeRdzNL 117
## 2 JoseAMeadeK 183
## 3 lopezobrador_ 73
## 4 Mzavalagc 190
## 5 RicardoAnayaC 15313.3.3 Palabras Positivas
Y veamos también las palabras positivas y negativas más usadas por cada uno de ellos, usando map() de purr, top_n() de dplyr() y ggplot.
map(c("Positiva", "Negativa"), function(sentimiento) {
tuits_afinn %>%
filter(Tipo == sentimiento) %>%
group_by(Candidato) %>%
count(Palabra, sort = T) %>%
top_n(n = 10, wt = n) %>%
ggplot() +
aes(Palabra, n, fill = Candidato) +
geom_col() +
facet_wrap("Candidato", scales = "free") +
scale_y_continuous(expand = c(0, 0)) +
coord_flip() +
labs(title = sentimiento) +
tema_graf
})## [[1]]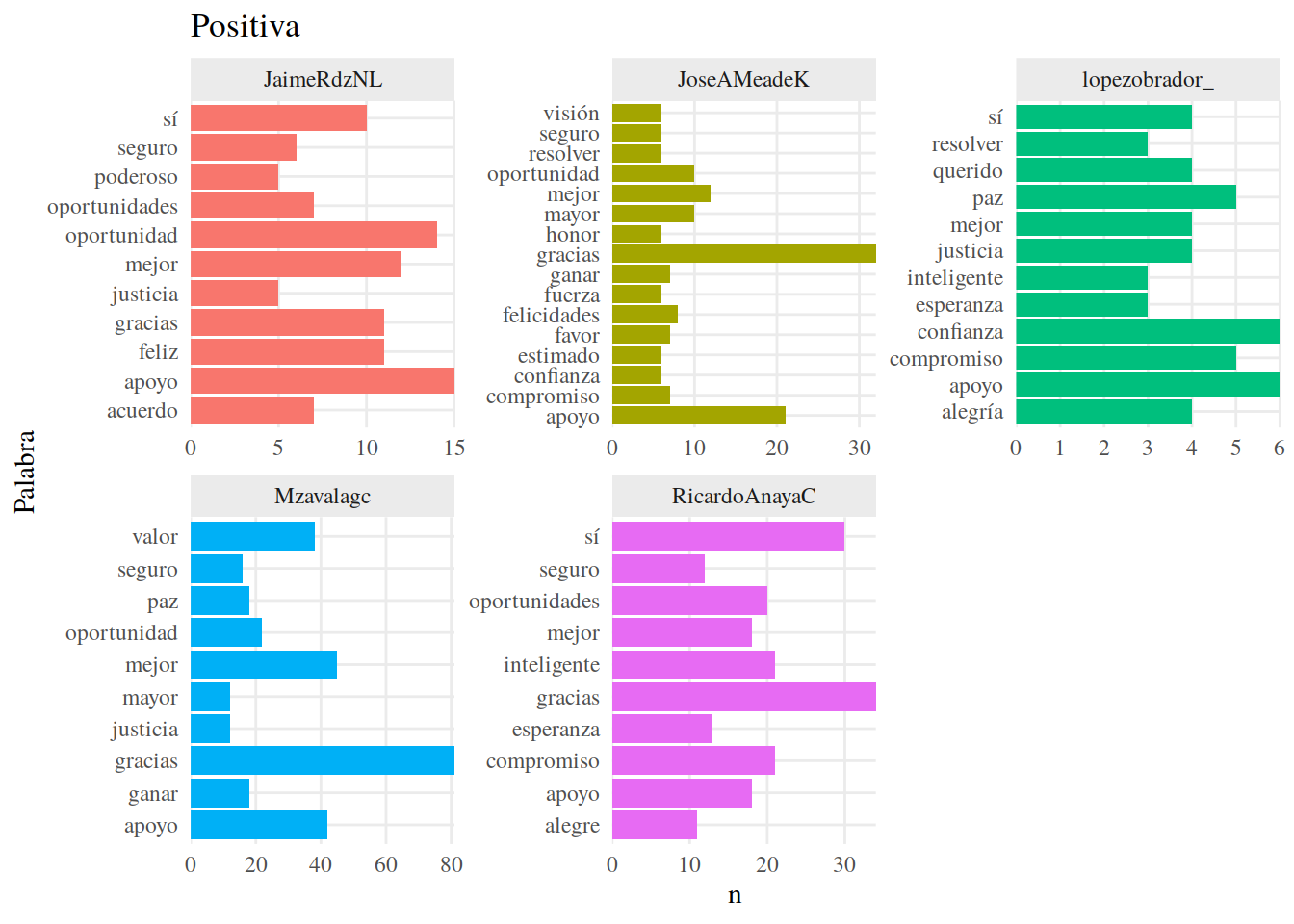
##
## [[2]]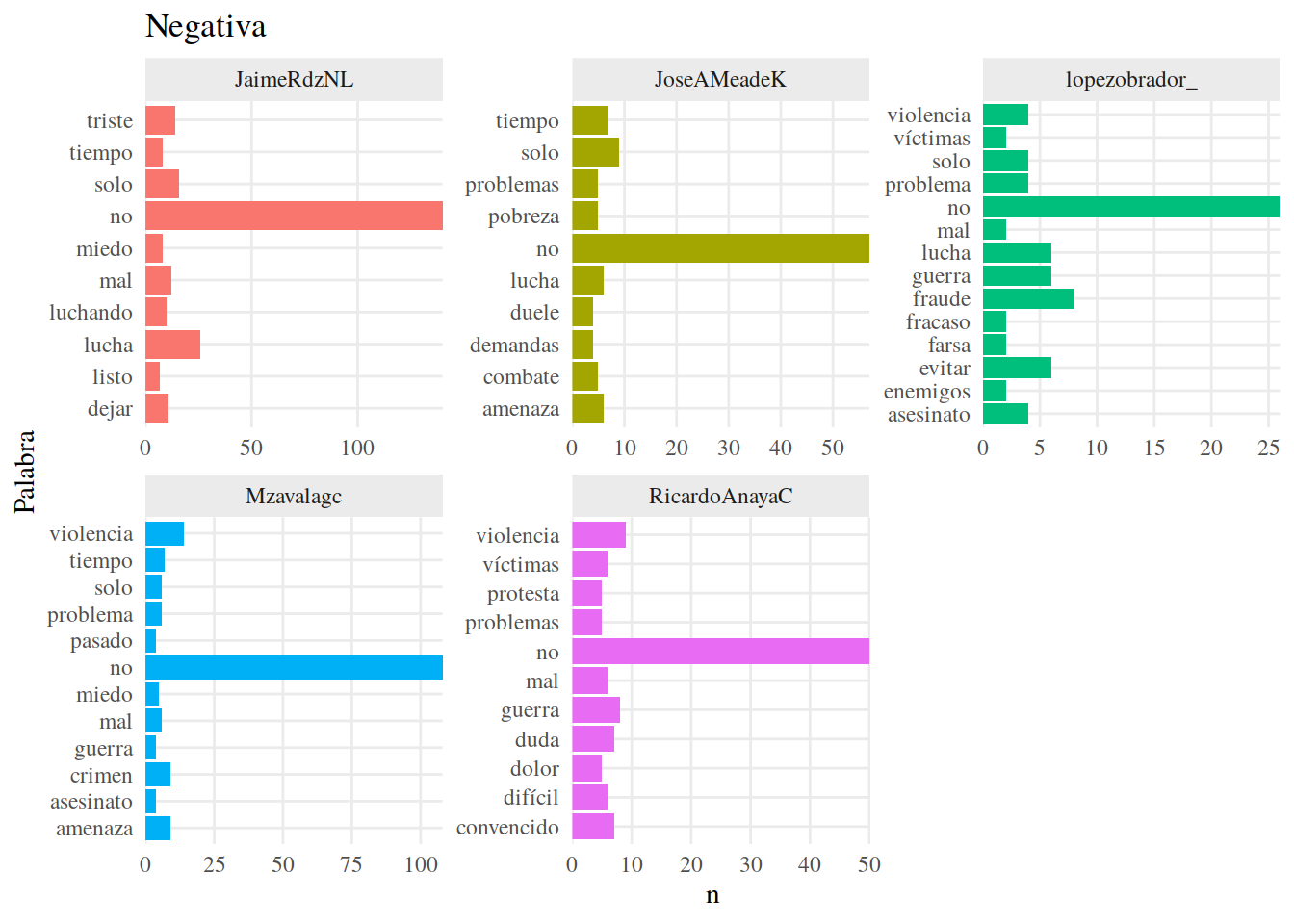
13.3.4 Similitudes
Aunque hay similitudes en las palabras usadas, también observamos una diferencia considerable en la cantidad de palabras usadas por el candidato con menos palabras (157, 72 únicas de lopezobrador_) y la candidata con más (730, 189 únicas de Mzavalagc).
Si calculamos el sentimiento de los candidatos, haciendo una suma de puntuaciones, aquellos con más palabras podrían tener puntuaciones más altas, lo cual sesgaría nuestra interpretación de la magnitud de los resultados. En un caso como este, nos conviene pensar en una medida resumen como la media para hacer una mejor interpretación de nuestros datos.
Quitamos “no” de nuestras palabras. Es una palabra muy comun en español que no necesariamente implica un sentimiento negativo. Es la palabra negativa más frecuente entre los candidatos, por lo que podría sesgar nuestros resultados.
13.3.5 Resultados
tuits_afinn <-
tuits_afinn %>%
filter(Palabra != "no") 13.3.6 Tendencias
Como deseamos observar tendencias, vamos a obtener la media de sentimientos por día, usando group_by() y summarise() y asignamos los resultados a tuits_afinn_fecha
tuits_afinn_fecha <-
tuits_afinn %>%
group_by(status_id) %>%
mutate(Suma = mean(Puntuacion)) %>%
group_by(Candidato, Fecha) %>%
summarise(Media = mean(Puntuacion))13.3.7 Ploteo de resultados
Veamos nuestros resultados con ggplot()
tuits_afinn_fecha %>%
ggplot() +
aes(Fecha, Media, color = Candidato) +
geom_line() +
tema_graf +
theme(legend.position = "top")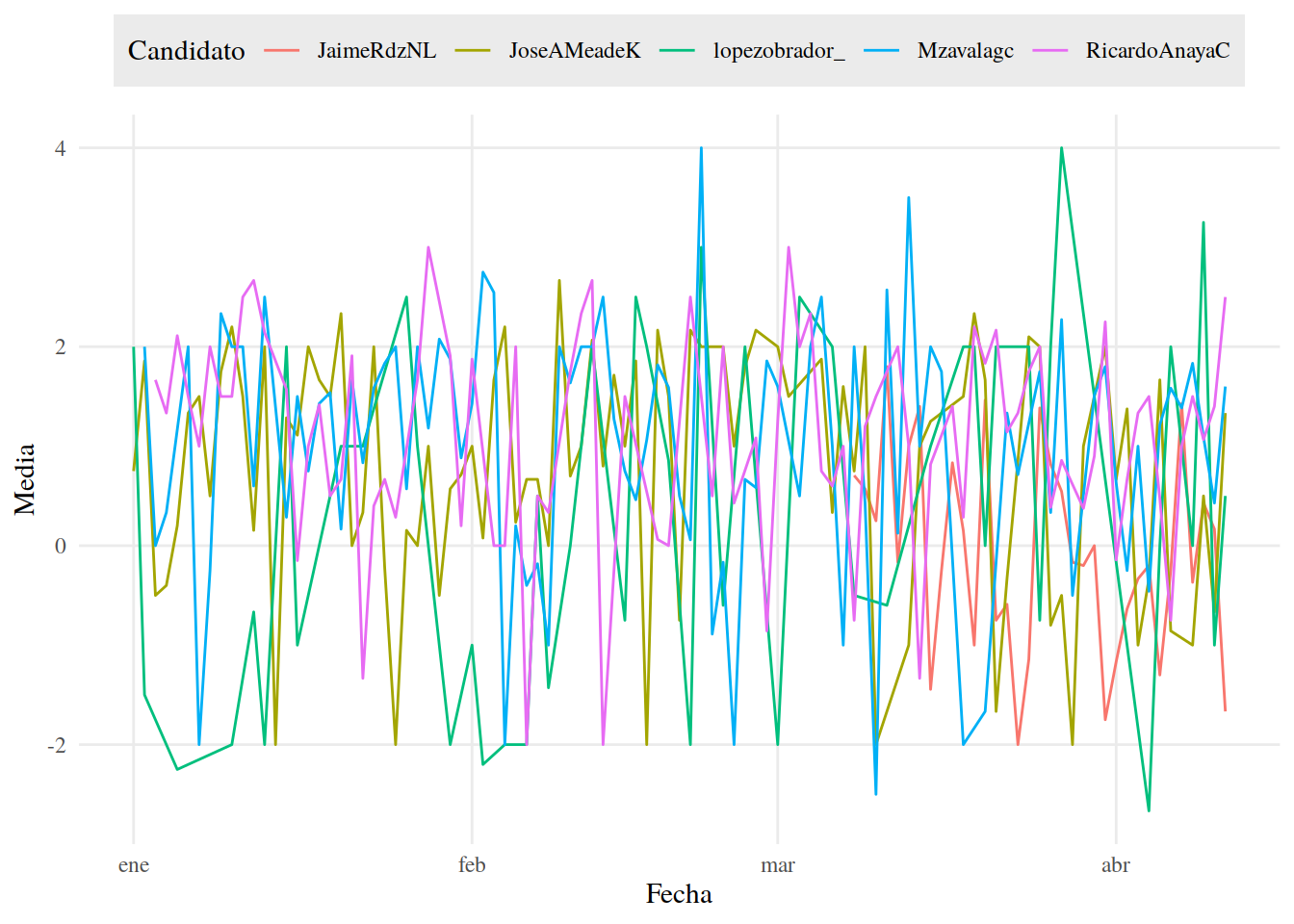
13.3.8 Tendencia de Candidatos
No nos dice mucho. Sin embargo, si separamos las líneas por candidato, usando facet_wrap(), será más fácil observar el las tendencias de los Candidatos.
tuits_afinn_fecha %>%
ggplot() +
aes(Fecha, Media, color = Candidato) +
geom_hline(yintercept = 0, alpha = .35) +
geom_line() +
facet_grid(Candidato~.) +
tema_graf +
theme(legend.position = "none")
13.3.9 Usando LOESS (regression local)
Una manera en que podemos extraer tendencias es usar el algoritmo de regresión local LOESS. Con este algoritmo trazaremos una línea que intenta ajustarse a los datos contiguos. Como sólo tenemos una observación por día, quitaremos el sombreado que indica el error estándar.
Una explicación más completa de LOESS se encuentra aquí:
https://www.itl.nist.gov/div898/handbook/pmd/section1/pmd144.htm Usamos la función geom_smooth() de ggplot2, con el argumento method = "loess" para calcular y graficar una regresión local a partir de las medias por día.
13.3.10 LOESS
tuits_afinn_fecha %>%
ggplot() +
aes(Fecha, Media, color = Candidato) +
geom_smooth(method = "loess", fill = NA) +
tema_graf## `geom_smooth()` using formula 'y ~ x'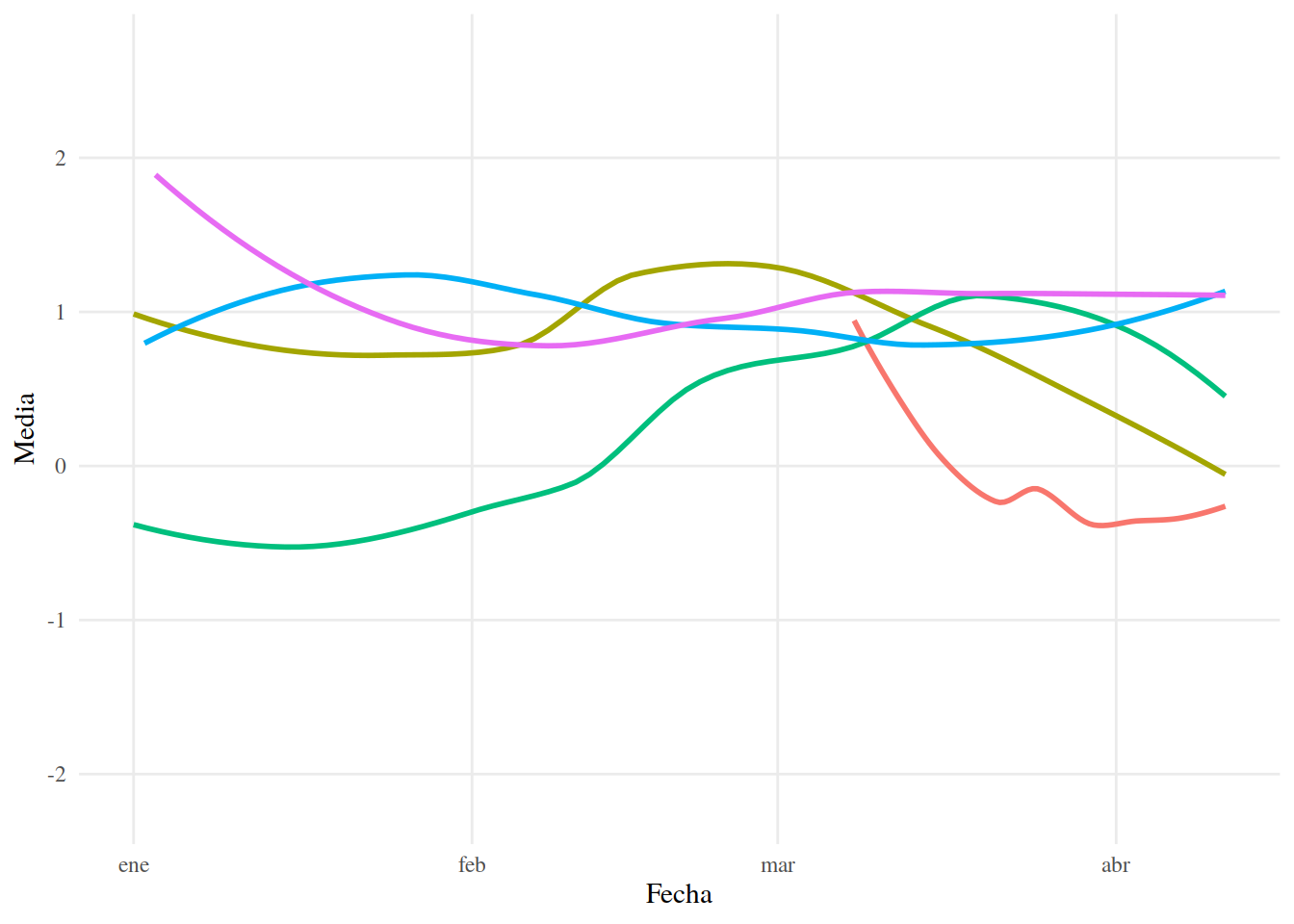
En realidad, podemos obtener líneas muy similares directamente de las puntuaciones.
tuits_afinn %>%
ggplot() +
aes(Fecha, Puntuacion, color = Candidato) +
geom_smooth(method = "loess", fill = NA) +
tema_graf## `geom_smooth()` using formula 'y ~ x'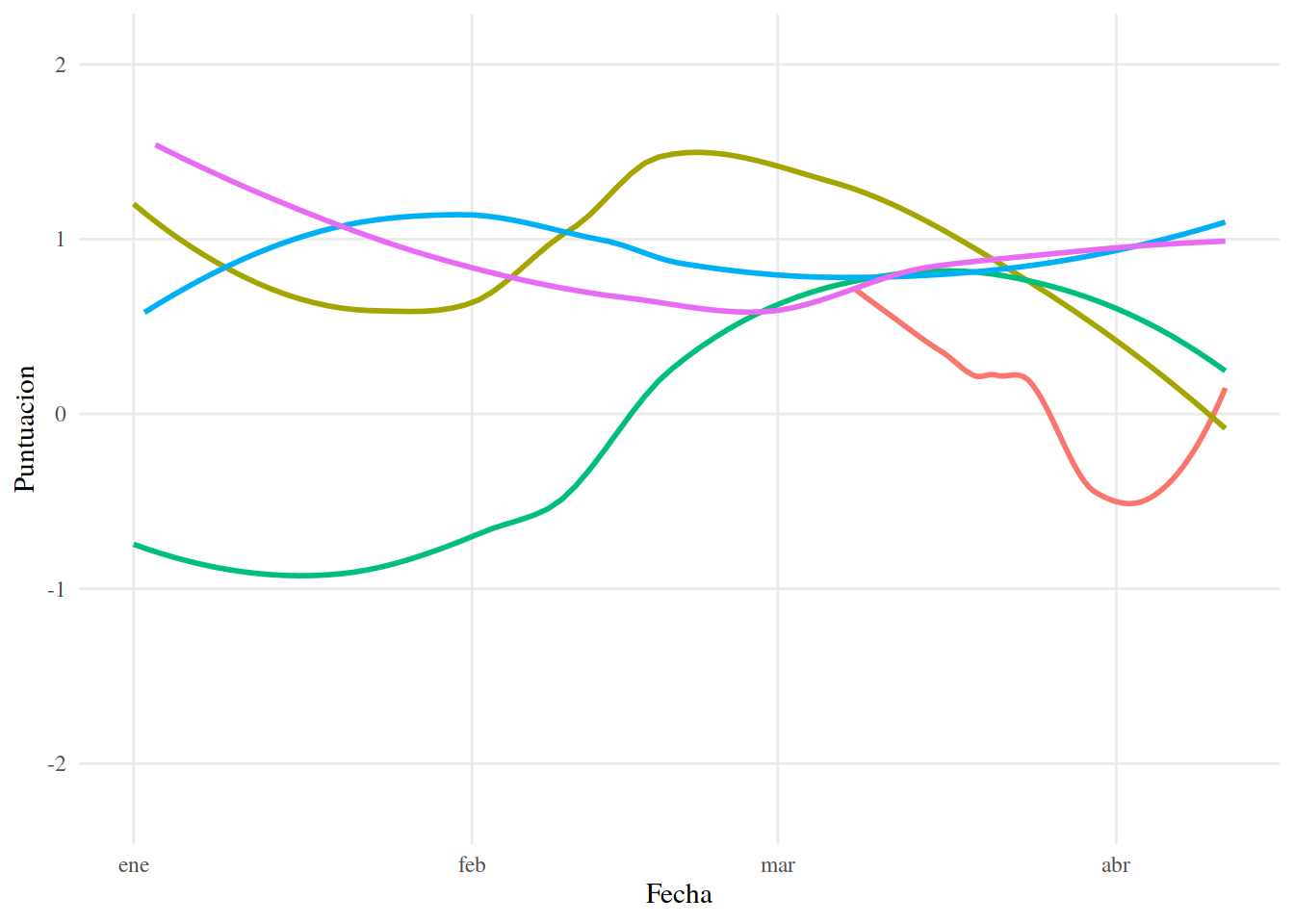
Lo anterior ilustra la manera en que el algoritmo LOESS llega a sus resultados. También es manera de observar que este algoritmo no nos permite obtener una formula de regresión, de la misma manera que lo haríamos
Si separamos las lineas por candidato y mostramos los puntos a partir de los cuales se obtienen las líneas de regresión, podemos observar con más claridad la manera en que el algoritmo LOESS llega a sus resultado. Haremos esto con facet_wrap() y geom_point.
13.3.11 Tendencia
tuits_afinn %>%
ggplot() +
aes(Fecha, Puntuacion, color = Candidato) +
geom_point(color = "#E5E5E5") +
geom_smooth(method = "loess", fill = NA) +
facet_wrap(~Candidato) +
tema_graf## `geom_smooth()` using formula 'y ~ x'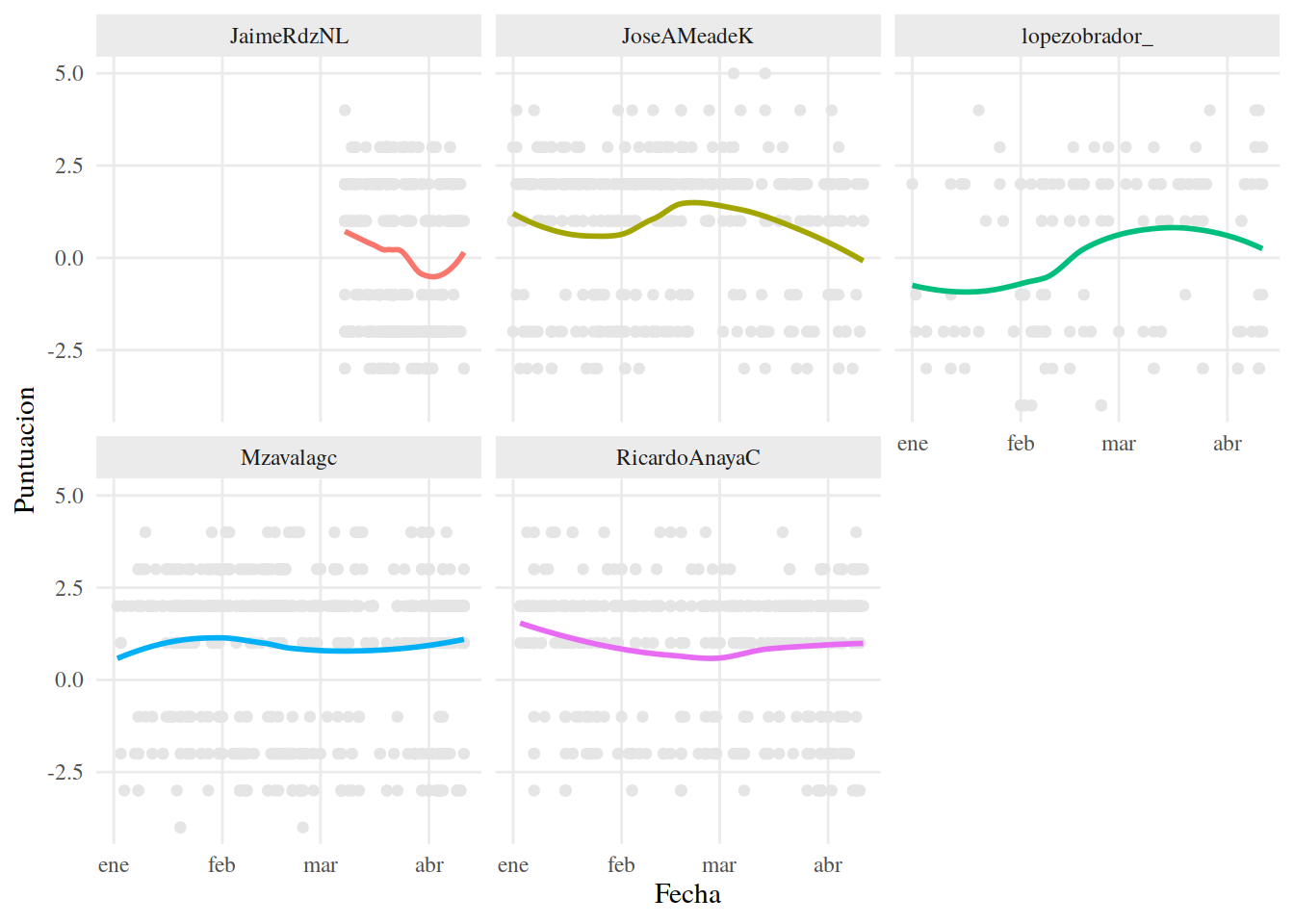
13.3.12 Identificación
Esto es conveniente, pues podemos identificar tendencias de datos que en apariencia no tienen ninguna. Al mismo tiempo, esto es una desventaja, pues podemos llegar a sobre ajustar la línea de regresión y, al interpretarla, llegar a conclusiones que no siempre son precisas.
Comparemos los resultados de al algoritmo LOESS con los resultados de una Regresión Lineal ordinaria, que intentará ajustar una recta.
13.3.13 Ajuste Lineal
tuits_afinn_fecha %>%
ggplot() +
aes(Fecha, Media, color = Candidato) +
geom_point(color = "#E5E5E5") +
geom_smooth(method = "lm", fill = NA) +
facet_wrap(~Candidato) +
tema_graf## `geom_smooth()` using formula 'y ~ x'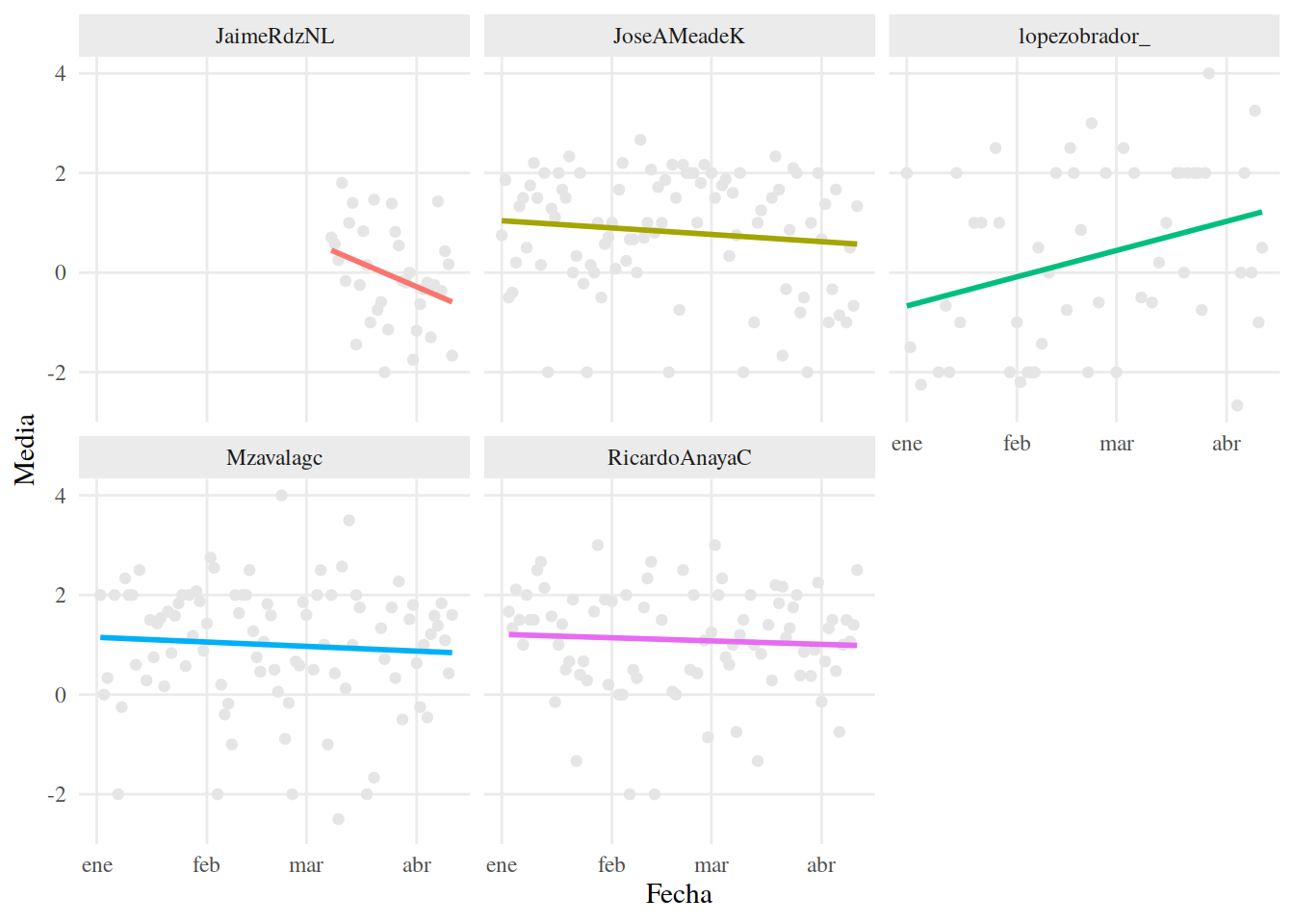
13.3.14 Clarificación
Aun podemos observar una tendencia, pero en la mayoría de los casos no es tan “clara” como parecería usando LOESS. También podemos ver cómo es que pocos datos, es posible que valores extremos cambien notablemente la forma de una línea trazada con LOESS, de manera similar a cómo cambian la pendiente de una Regresión Lineal ordinaria. Esto es osbervable con los datos de lopezobrador_.
Para nuestros fines, LOESS es suficiente para darnos un panorama general en cuanto a la tendencia de sentimientos en los candidatos. No obstante, es importante ser cuidadosos con las interpretaciones que hagamos.
13.3.15 Usando la media móvil
La media móvil se obtiene a partir de subconjuntos de datos que se encuentran ordenados. En nuestro ejemplo, tenemos nuestros datos ordenados por fecha, por lo que podemos crear subconjuntos de fechas consecutivas y obtener medias de ellos. En lugar de obtener una media de puntuación de todas las fechas en nuestros datos, obtenemos una media de los días 1 al 3, después de los días 2 al 4, después del 3 al 5, y así sucesivamente hasta llegar al final de nuestras fechas.
Lo que obtendríamos con esto son todos los agregados de tres días consecutivos, que en teoría debería ser menos fluctuantes que de los días individuales, es decir, más estables y probablemente más apropiados para identificar tendencias.
Crearemos medias móviles usando rollmean() de zoo. Con esta función calculamos la media de cada tres días y la graficamos con ggplot.
13.3.16 Media Móvil
tuits_afinn_fecha %>%
group_by(Candidato) %>%
mutate(MediaR = rollmean(Media, k = 3, align = "right", na.pad = TRUE)) %>%
ggplot() +
aes(Fecha, MediaR, color = Candidato) +
geom_hline(yintercept = 0, alpha = .35) +
geom_line() +
facet_grid(Candidato~.) +
tema_graf## Warning: Removed 10 row(s) containing missing
## values (geom_path).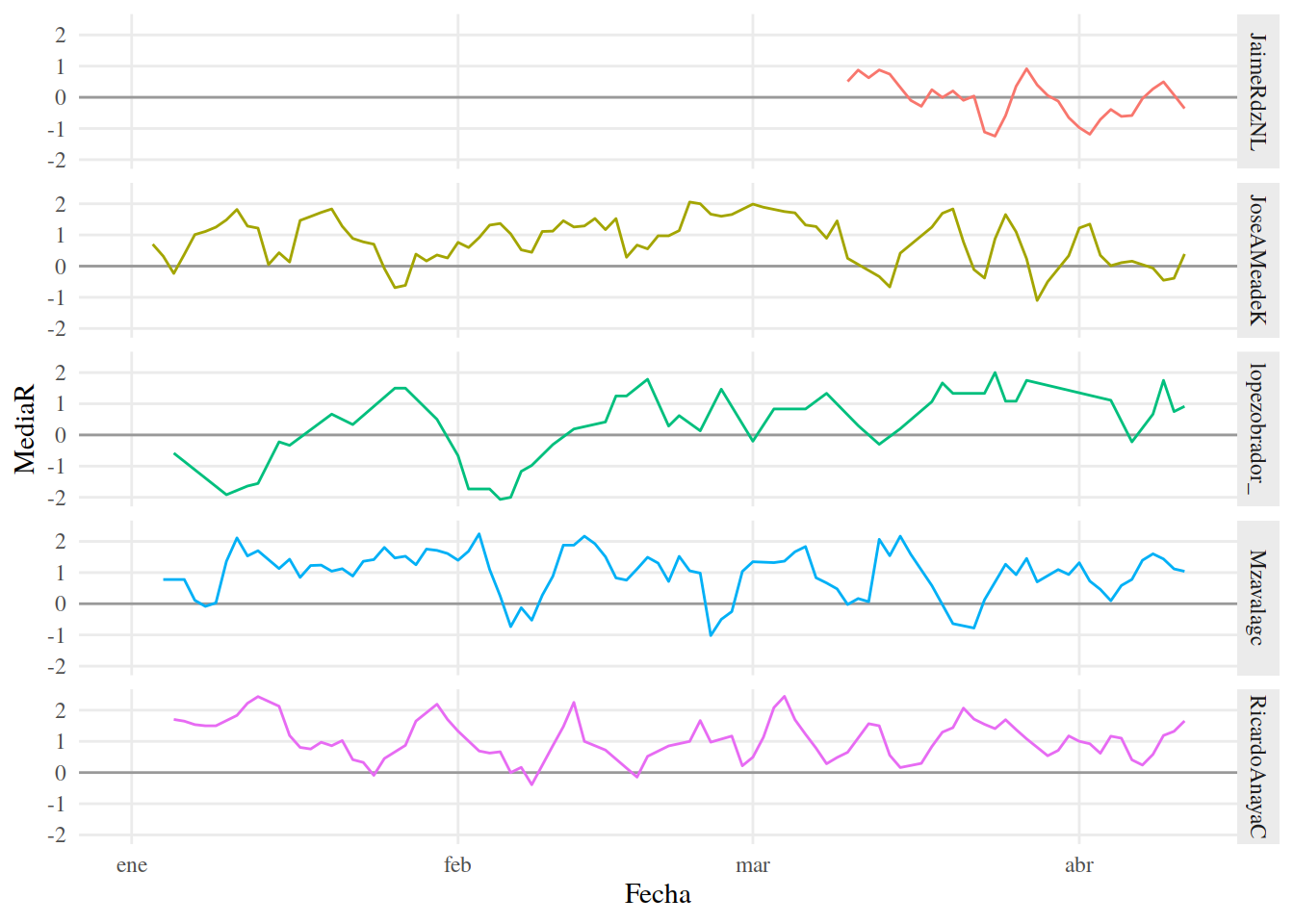
13.3.17 Comparación de Gráficas
Si comparamos con la gráfica que obtuvimos a partir de las medias por día, esta es menos “ruidosa” y nos permite observar más fácilmente las tendencias.
Comparando sentimientos positivos y negativos Es posible que no nos interen las puntuaciones de sentimiento de cada día, sólo si la tendencia ha sido positiva o negativa. Como ya etiquetamos la puntuación de nuestros tuits como “Positiva” y “Negativa”, sólo tenemos que obtener proporciones y graficar.
Primero, veamos que proporción de tuits fueron positivos y negativos, para todo el 2018 y para cada Candidato. Usamos geom_col() de ggplot2 para elegir el tipo de gráfica y la función percent_format() de scales para dar formato de porcentaje al eje y.
13.3.18 Proporciones
tuits_afinn %>%
count(Candidato, Tipo) %>%
group_by(Candidato) %>%
mutate(Proporcion = n / sum(n)) %>%
ggplot() +
aes(Candidato, Proporcion, fill = Tipo) +
geom_col() +
scale_y_continuous(labels = percent_format()) +
tema_graf +
theme(legend.position = "top")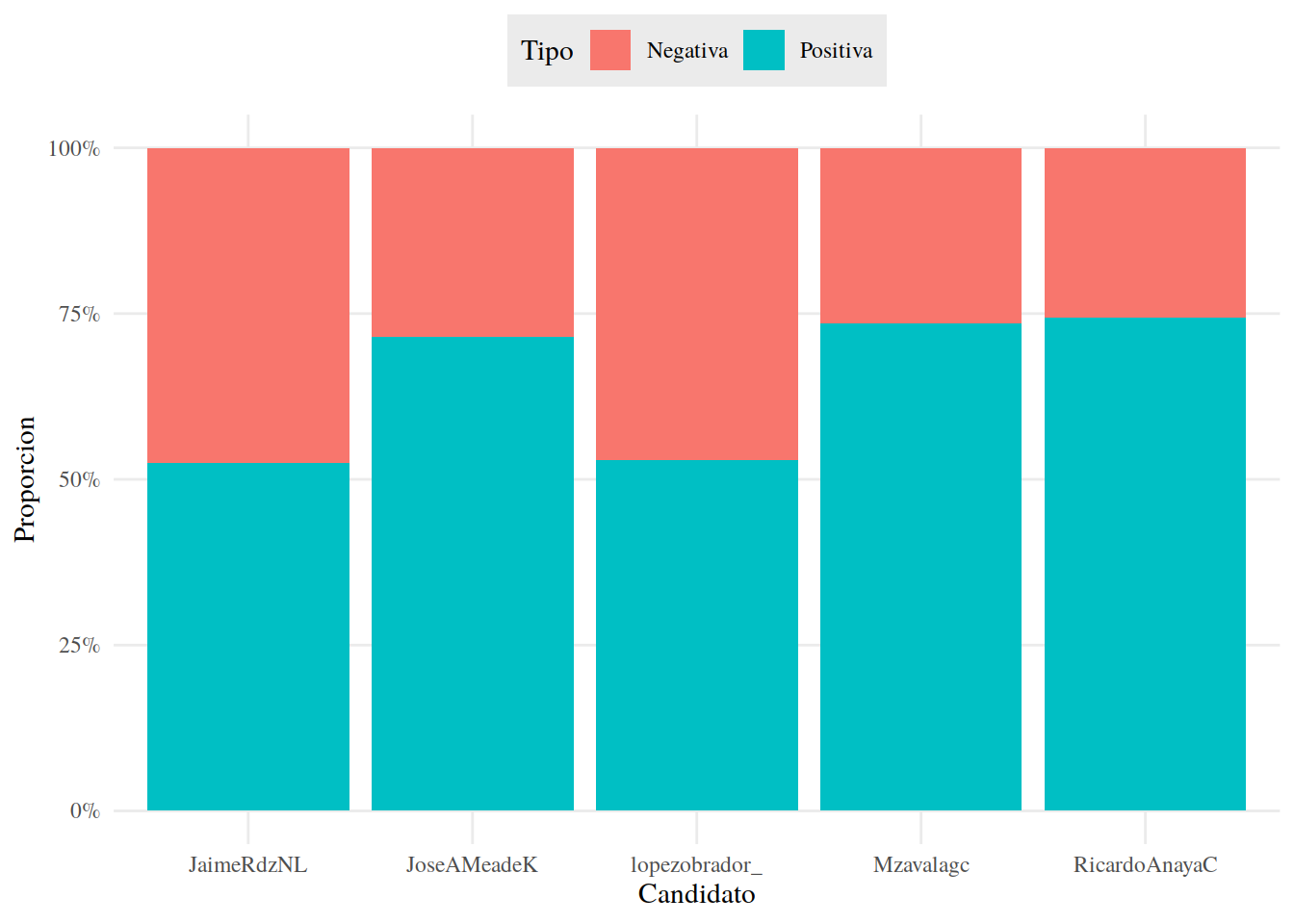
13.3.19 Imagen positiva y Negativa
Si obtnemos la proporción de positiva y negativa por día, podemos obsrvar cómo cambia con el paso del tiempo. Usamos el argumento width = 1 de geom_col() para quitar el espacio entre barras individuales y el argumento expand = c(0, 0) de scale_x_date() para quitar el espacio en blanco en los extremos del eje x de nuestra gráfica (intenta crear esta gráfica sin este argumento para ver la diferencia).
13.3.20 Imagen Positiva y Negativa por Fecha
tuits_afinn %>%
group_by(Candidato, Fecha) %>%
count(Tipo) %>%
mutate(Proporcion = n / sum(n)) %>%
ggplot() +
aes(Fecha, Proporcion, fill = Tipo) +
geom_col(width = 1) +
facet_grid(Candidato~.) +
scale_y_continuous(labels = percent_format()) +
scale_x_date(expand = c(0, 0)) +
tema_graf +
theme(legend.position = "top")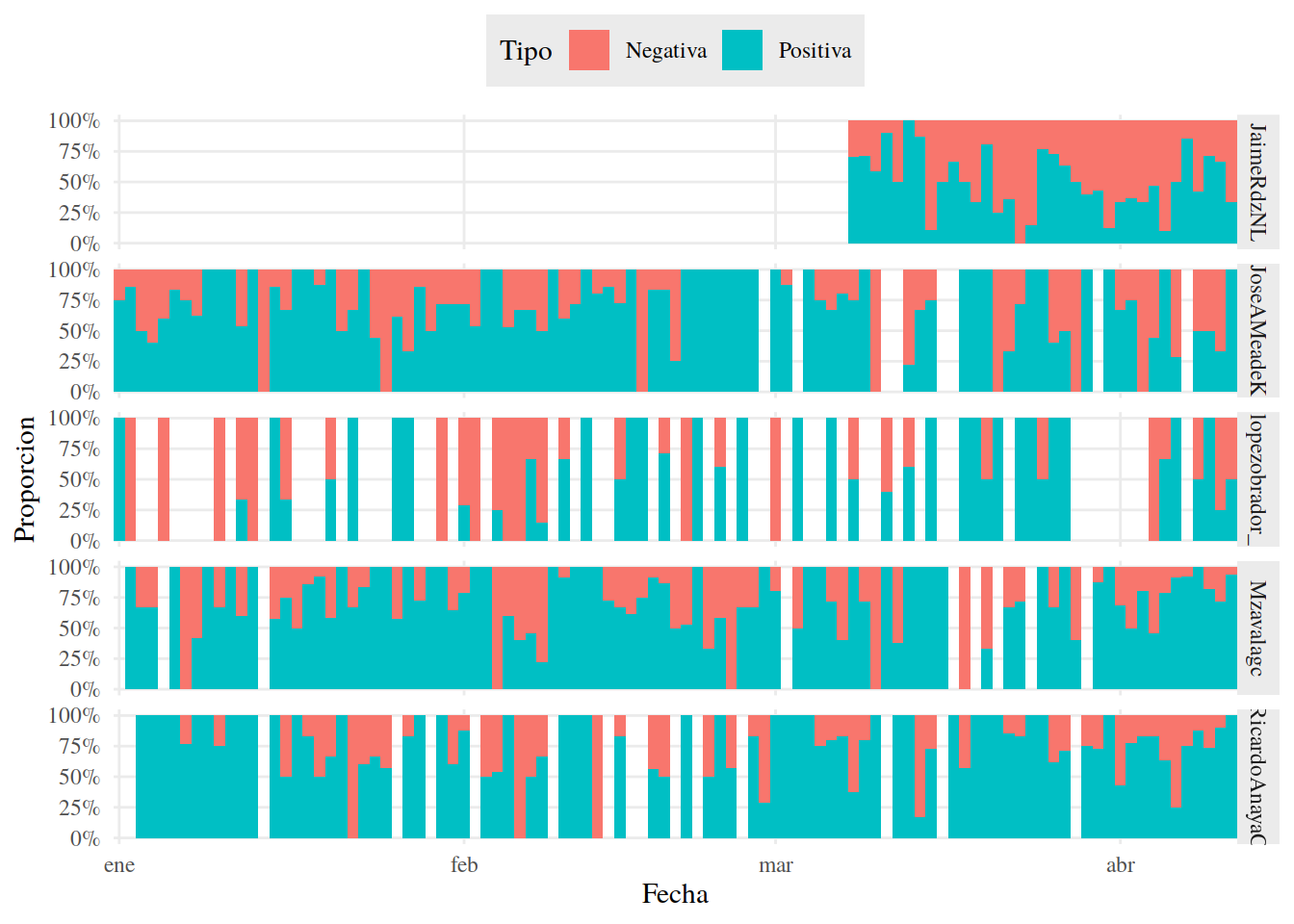
En este ejemplo, como los candidatos no tuitearon todos los días, tenemos algunos huecos en nuestra gráfica. De todos modos es posible observar la tendencia general de la mayoría de ellos.
13.3.21 Bloxplots (diagrama caja y bigotes)
Una manera más en la que podemos visualizar la puntuación sentimientos es usando boxplots. En nuestro análisis quizás no es la manera ideal de presentar los resultados dado que tenemos una cantidad relativamente baja de casos por Candidato. Sin embargo, vale la pena echar un vistazo, pues es una herramienta muy útil cuando tenemos una cantidad considerable de casos por analizar.
En este tipo de gráficos, la caja representa el 50% de los datos, su base se ubica en el primer cuartil (25% de los datos debajo) y su tope en el tercer cuartil (75% de los datos debajo). La línea dentro de la caja representa la mediana o secundo cuartil (50% de los datos debajo). Los bigotes se extienden hasta abarcar un largo de 1.5 veces el alto de la caja, o hasta abarcar todos los datos, lo que ocurra primero. Los puntos son los outliers, datos extremos que salen del rango de los bigotes. Por todo lo anterior, esta visualización es preferible cuando tenemos datos con distribuciones similares a una normal.
Usamos la función geom_boxplot() de ggplot2 para elegir el tipo de gráfica. Creamos un boxplot por candidato.
13.3.22 Boxplot
tuits %>%
ggplot() +
aes(Candidato, Puntuacion_tuit, fill = Candidato) +
geom_boxplot() +
tema_graf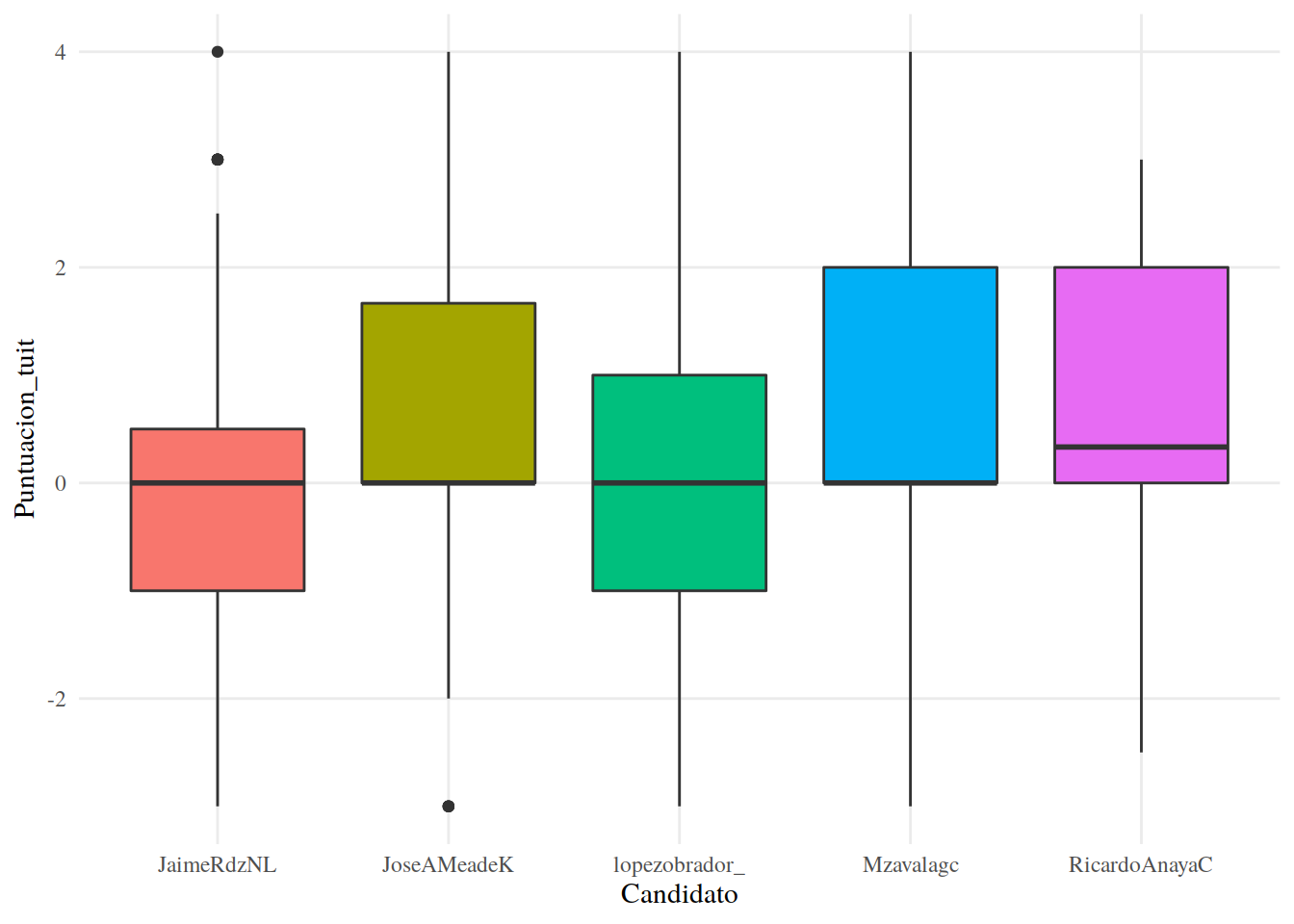
13.3.23 Dinámica de los cambios
También podemos crear boxplots para ver cambios a través del tiempo, sólo tenemos que agrupar nuestros datos. Como nuestros datos ya tienen una columna para el mes del año, usaremos esa como variable de agrupación. Nota que usamos factor() dentro de mutate() para cambiar el tipo de dato de Mes, en R los boxplots necesitan una variable discreta en el eje x para mostrarse correctamente.
13.3.24 Dinámica
tuits %>%
mutate(Mes = factor(Mes)) %>%
ggplot() +
aes(Mes, Puntuacion_tuit, fill = Candidato) +
geom_boxplot(width = 1) +
facet_wrap(~Candidato) +
tema_graf +
theme(legend.position = "none")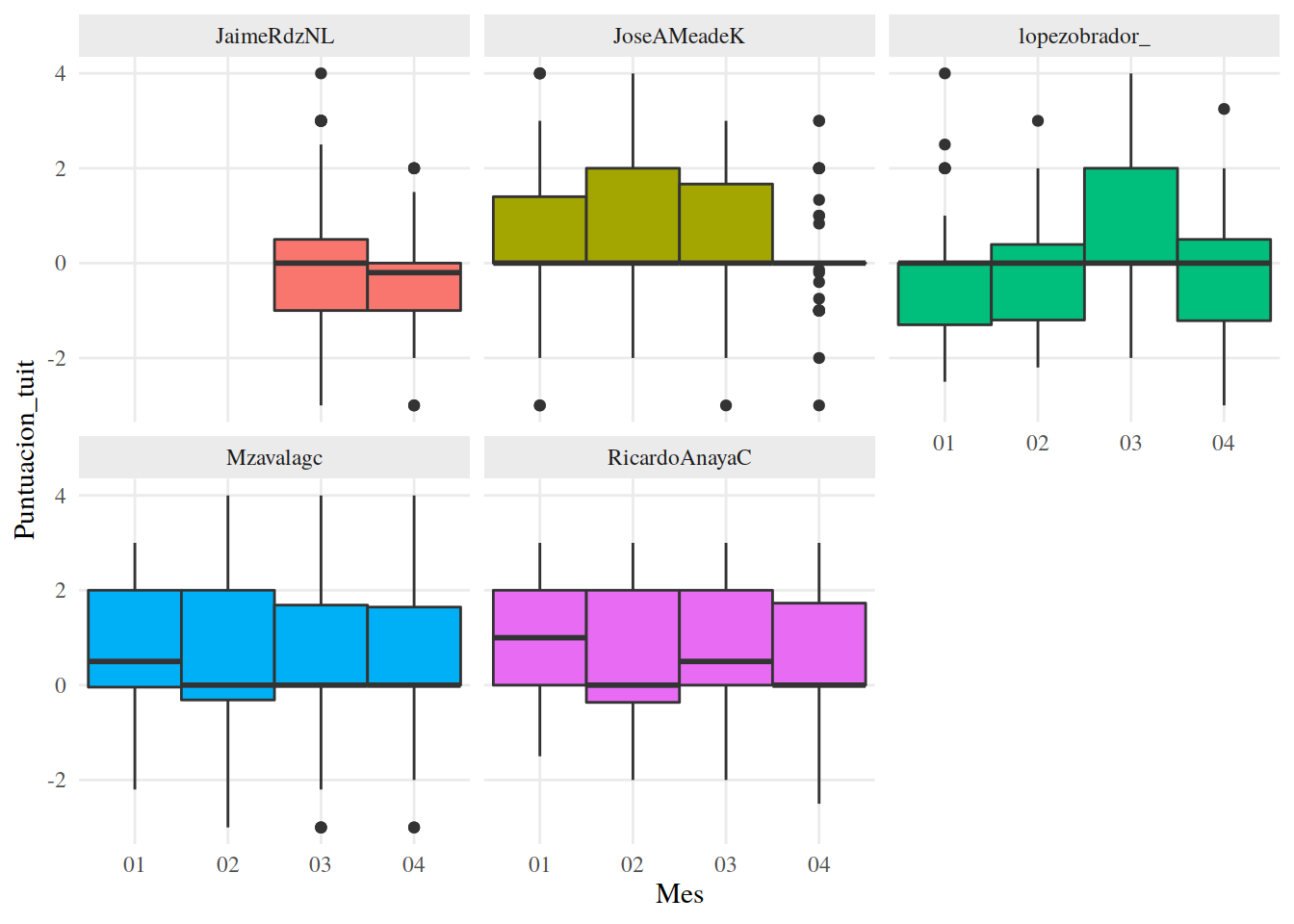
13.3.25 Usando densidades
Por último, podemos analizar las tendencias de sentimientos usando las funciones de densidad de las puntuaciones. ggplot2 tiene la función geom_density() que hace muy fácil crear y graficar estas funciones.
13.3.26 Densidad
tuits %>%
ggplot() +
aes(Puntuacion_tuit, color = Candidato) +
geom_density() +
facet_wrap(~Candidato) +
tema_graf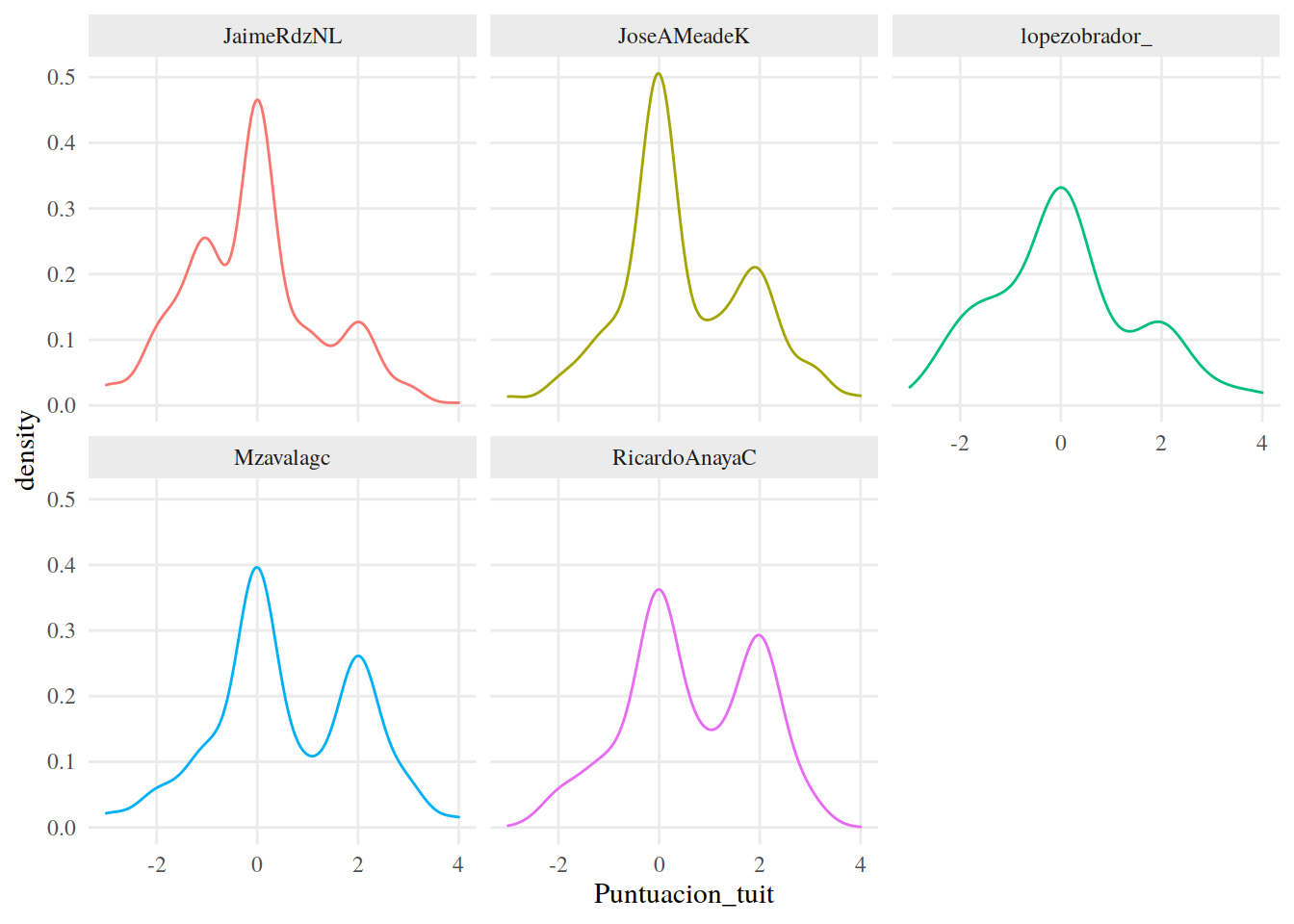
13.3.27 Tendencias Dinámicas
Por supuesto, también podemos observar las tendencias a través del tiempo usando facet_grid() para crear una cuadrícula de gráficas, con los candidatos en el eje x y los meses en el eje y.
tuits %>%
ggplot() +
aes(Puntuacion_tuit, color = Candidato) +
geom_density() +
facet_grid(Candidato~Mes) +
tema_graf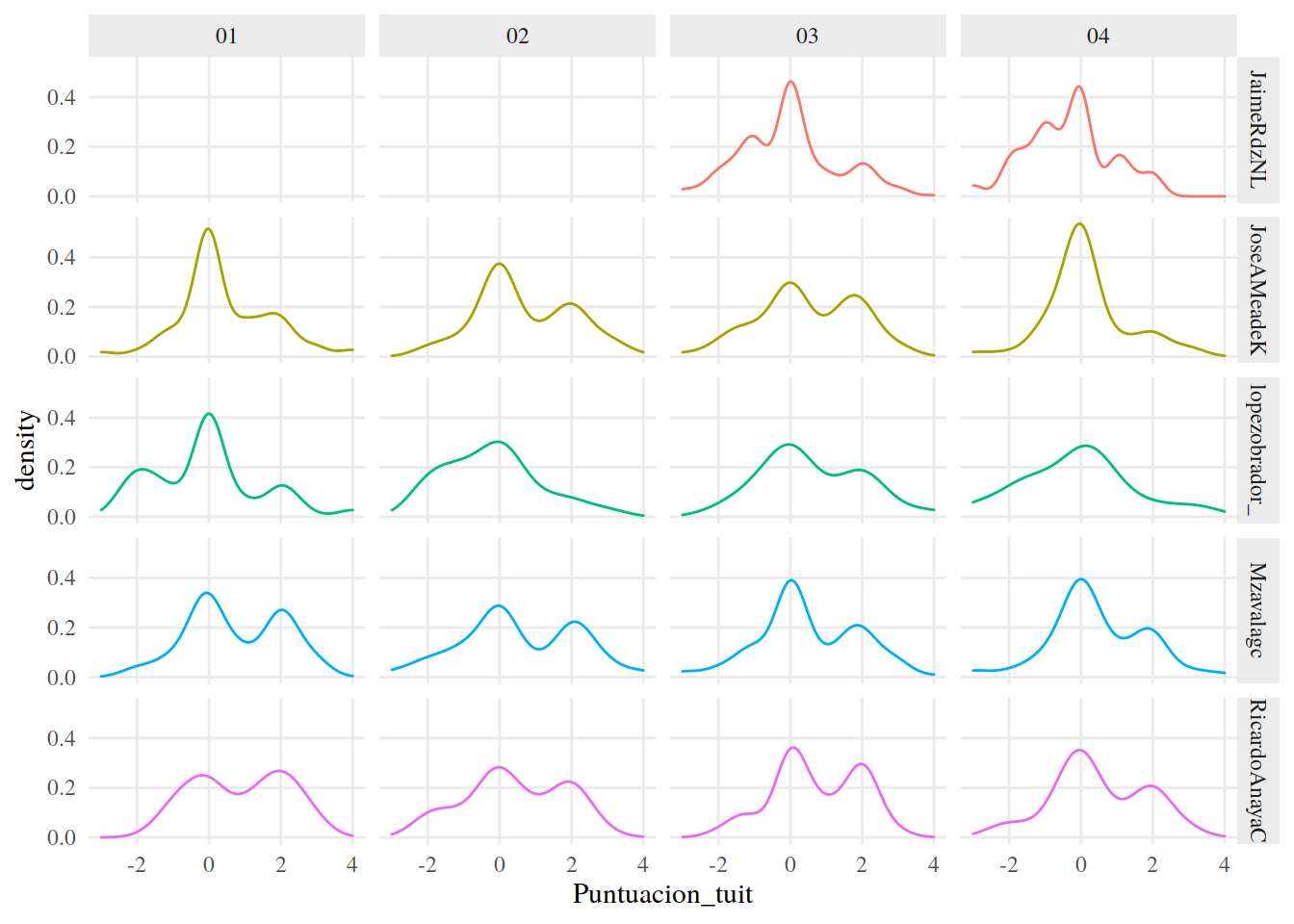
13.4 Conclusiones del análisis de sentimiento
En este artículo revisamos algunas de las estrategias principales para analizar sentimientos con R, usando el léxico Afinn. Este léxico le asigna una puntuación a las palabras, de acuerdo a su contenido, que puede ser positivo o negativo.
En realidad, que la puntuación sea de tipo numérico es lo nos abre una amplia gama de posibilidades para analizar sentimientos usando el léxico Afinn. Con conjuntos de datos más grandes que el que usamos en este ejemplo, es incluso plausible pensar en análisis más complejos, por ejemplo, establer correlaciones y crear conglomerados.
Aunque no nos adentramos al análisis de los resultados que obtuvimos con nuestros datos, algunas tendencias se hicieron evidentes rápidamente. Por ejemplo, la mayoría de los candidatos ha tendido a tuitear de manera positiva. Con un poco de conocimiento del tema, sin duda podríamos encontrar información útil e interesante.