5 Primer taller de trabajo
Aquí se espondrán los trabajos realizados por cada grupo.
- Tarea principal
Creaer una archivo markdown con Tu nombre, fotografía, formación de grado, datos destacados de tu perfil, publicaciones, campo disciplinar de la teis que te gustaría realizar
- AREAS Y SUBÁREAS DEL CONOCIMIENTO UNESCO
Revisa estas área para identificar mejor el terreno de tu campo disciplinar.
- Reúne la hoja de vida que has construído con la de los compañeros de tu grupo de trabajo.
5.1 Encontrando a Antonov
Este ejercicio que dejamos para ir realizando seguramente ya te ha soprendido. Las consultas de los alumnos han superado la capacidad de nuestros celulares respecto a las fallas que presenta. A pesar de las dificultades encontradas, les comento que este es un dataset muy pequeño. No podemos considerarlo como un conjunto de BIG Data. Pero a pesar de ello a primera vista excel nos dice que es más grande que la cantidad máxima de filas y columnas que el puede manejar con la memoria que tienes en tu máquina. Lamento informar que esto es falso, incluso si lo administraos con R tendríamos algunos problemas. La diferencia es que en este caso dentro de R podemos solucionarlo.
5.1.1 Rescatas datos de excel dentro R-Cran
Vamos a introducir el concepto de "script" dentro de R. Un script o guión en una seire de comando de R que se guardan en un archivo de texto y se invocan para realizar esos pasos que necesitaremos ejecutar en forma repetitiva durante mucho tiempo.
Para ello debemos trabajar la creación desde menú.
Archivos -> Nuevo -> R-Script
Allí ejecutaremos los comandos que probaremos primero en la consola de R Studio.
5.1.2 Captura de Archivo Local
library(readr)
eana_012014_062019 <- read_delim("eana_012014_062019.csv",
";", escape_double = FALSE, trim_ws = TRUE)
Comentamos esta línea para que el script se ejecute
View(eana_012014_062019)Sin embargo aparece un error del tipo multibyte.
Cuando operamos con datos generados por máquinas, o que vienen con caracteres de otros lenguajes (crílico por ejemplo), o intervenen métodos de transmisión de radiofrecuencia que pueden ser interferidos tenemos que asegurarnos que todos los caractéres sean imprimobles.
Este script de R sólo funciona con Linux y comentaremos en el taller como hacer esto en Windows.
# Ejecutar en terminal
# iconv -t utf-8 -c eana_012014_062019.csv > eana_limpio.csv
# wc eana_eana_012014_062019.csv
# WC eana_limpio.csvEl comando iconv
Otra forma de trabajar el archivo ya despojado de caracteres o "basura" se puede ejecutar el comando para obtener los datos desde la página de web.
library(readr)eana_limpio <- read_delim("https://themys.sid.uncu.edu.ar/~rpalma/R-cran /Analitica_Industrial/eana_limpio.csv", ";", escape_double = FALSE, trim_ws = TRUE)
A así ya estamos en condiciones para realizar trabajos.
Utilizaremos algunso comando de la consolo que iremos estudiando.
? grepA partir de aqui subiremos los apunte de clase de los alumnos
- Aislar los registros de un aeropuerto
Buscar los registro de Antonov en ese rango.
grep("AN" , SAME_limpio$Aeronave) -> antonov SAME_limpio[antonov, ] SAME_limpio[antonov, ] -> leer View(leer)
5.2 Manejo de datos y estructuras
Agrega aquí tus notas.
** Eficiencia Energética**
eficiency <- read.table("http://ceal.fing.uncu.edu.ar/r-cran/solar.txt",header = TRUE)5.2.1 ¿Qué columnas tienen esta tabla?
names(eficiency)## [1] "kWh" "gas" "solar"5.2.2 Pequeño análisis multivariado
pairs(eficiency, main="Matriz de Covarianza")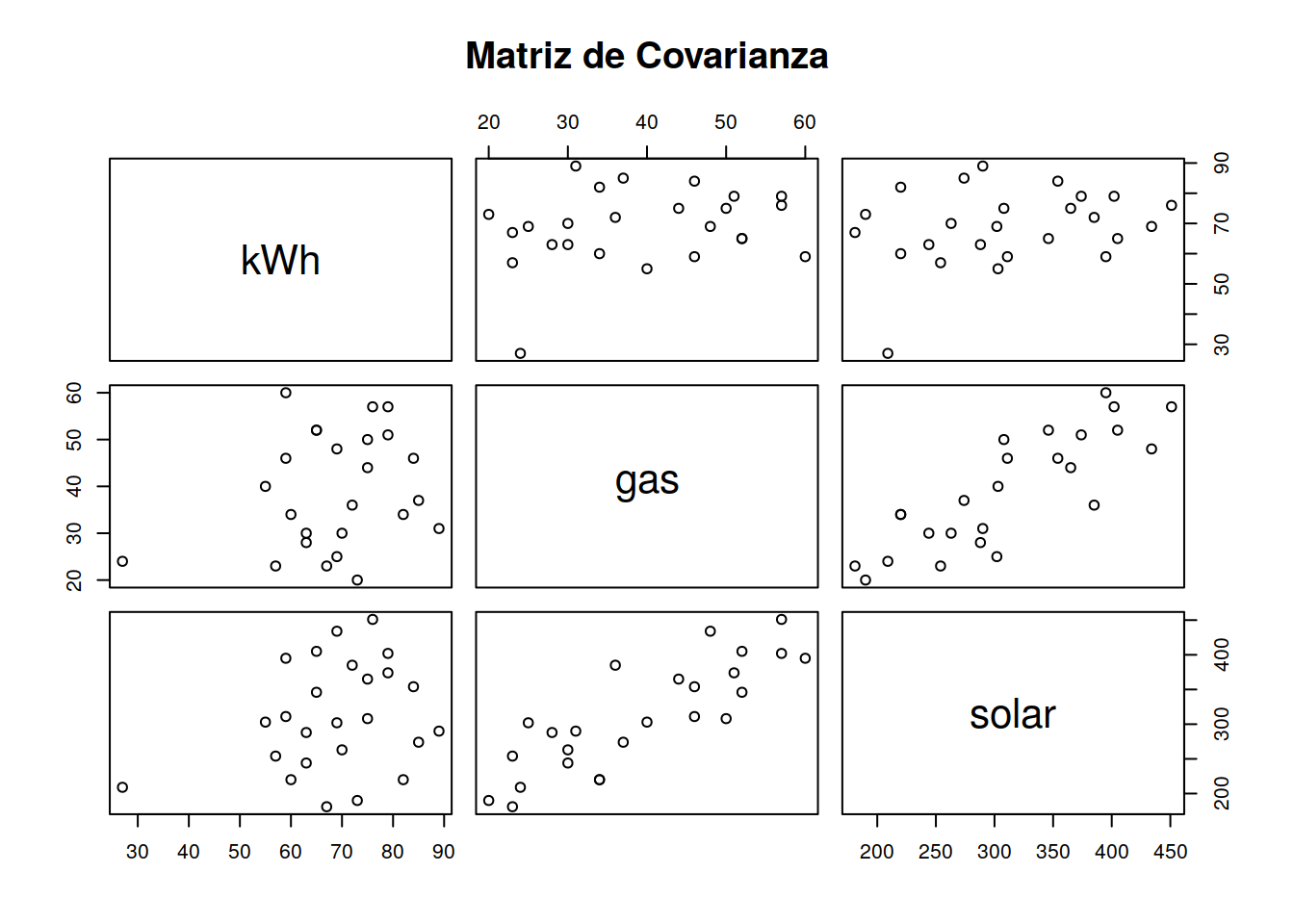
5.2.3 Estudio más detallado
library(psych)
pairs.panels(eficiency)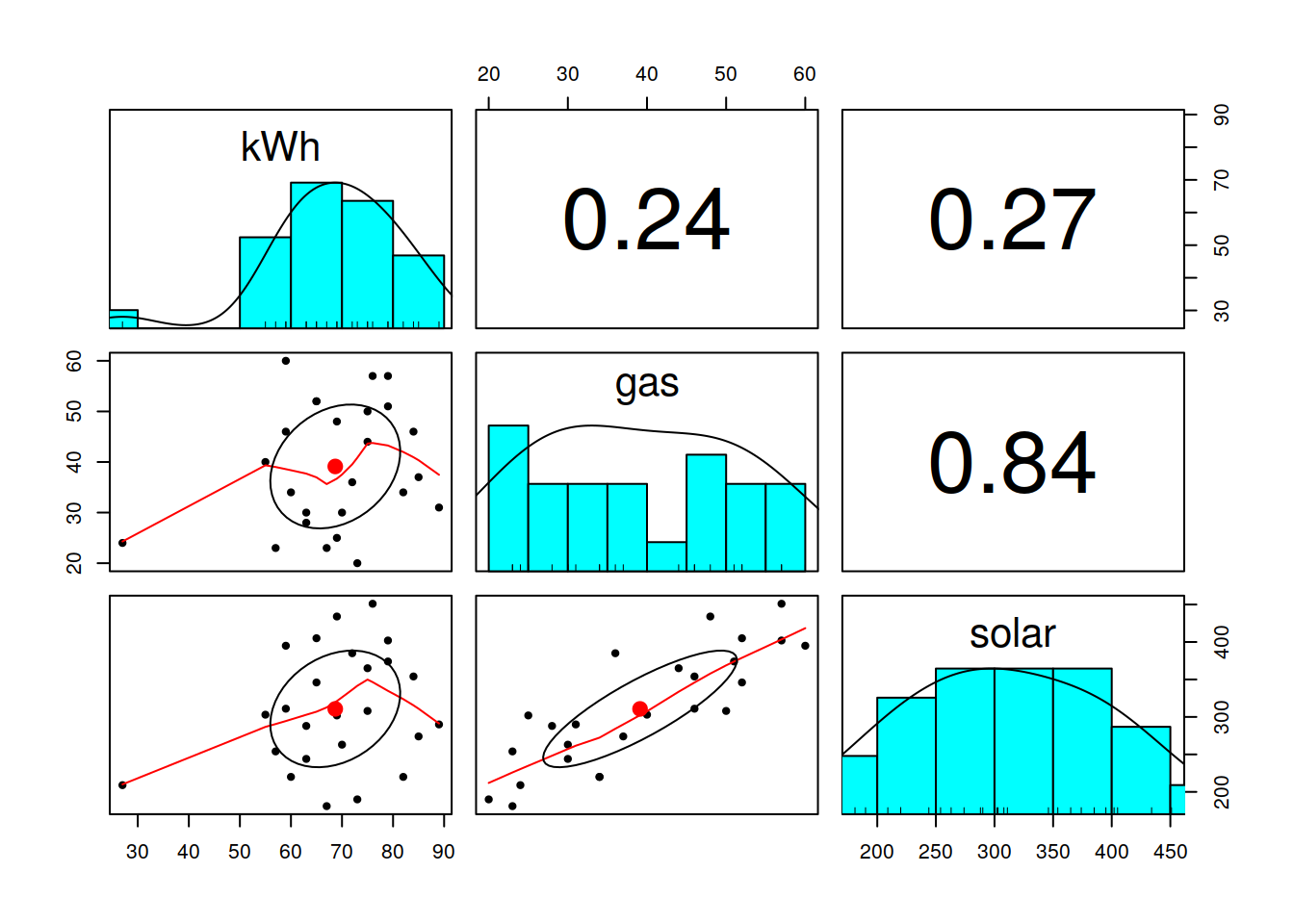
multi.hist(eficiency)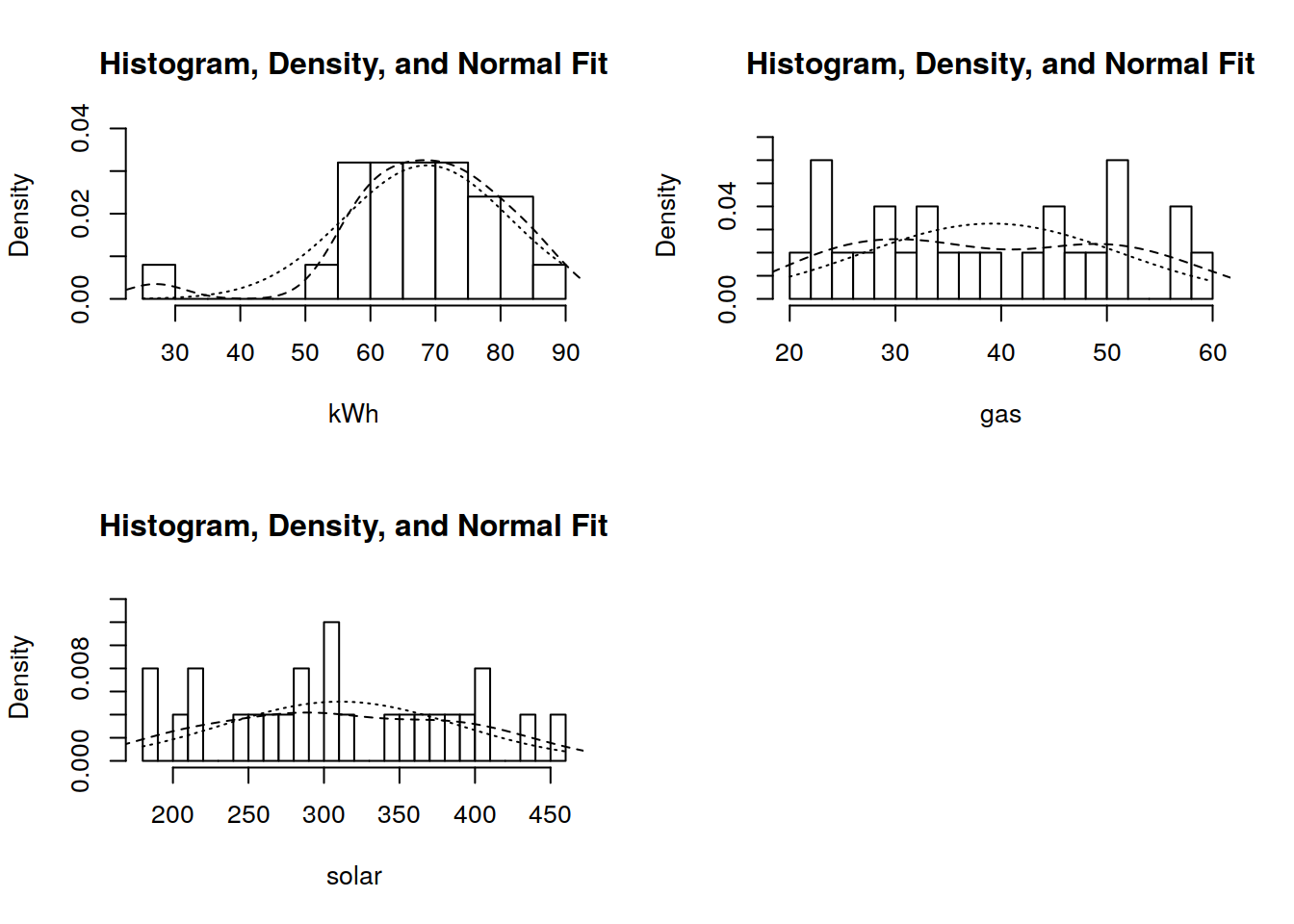
cor(eficiency)## kWh gas solar
## kWh 1.0000000 0.2400133 0.2652935
## gas 0.2400133 1.0000000 0.8373534
## solar 0.2652935 0.8373534 1.00000005.2.4 Calidad del modelo
¿Que tan buena puede ser la correlación que obtendíamos?
regresion <- lm(solar ~ gas, data = eficiency)
summary(regresion)##
## Call:
## lm(formula = solar ~ gas, data = eficiency)
##
## Residuals:
## Min 1Q Median 3Q Max
## -63.478 -26.816 -3.854 28.315 90.881
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 102.5751 29.6376 3.461 0.00212 **
## gas 5.3207 0.7243 7.346 1.79e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 43.46 on 23 degrees of freedom
## Multiple R-squared: 0.7012, Adjusted R-squared: 0.6882
## F-statistic: 53.96 on 1 and 23 DF, p-value: 1.794e-075.2.5 Comparación
Comparación gráfica del modelo de regresión lineal
plot(eficiency$gas, eficiency$solar, xlab = "gas m^3 propano/butano", ylab = "solar cm^2")
abline(regresion)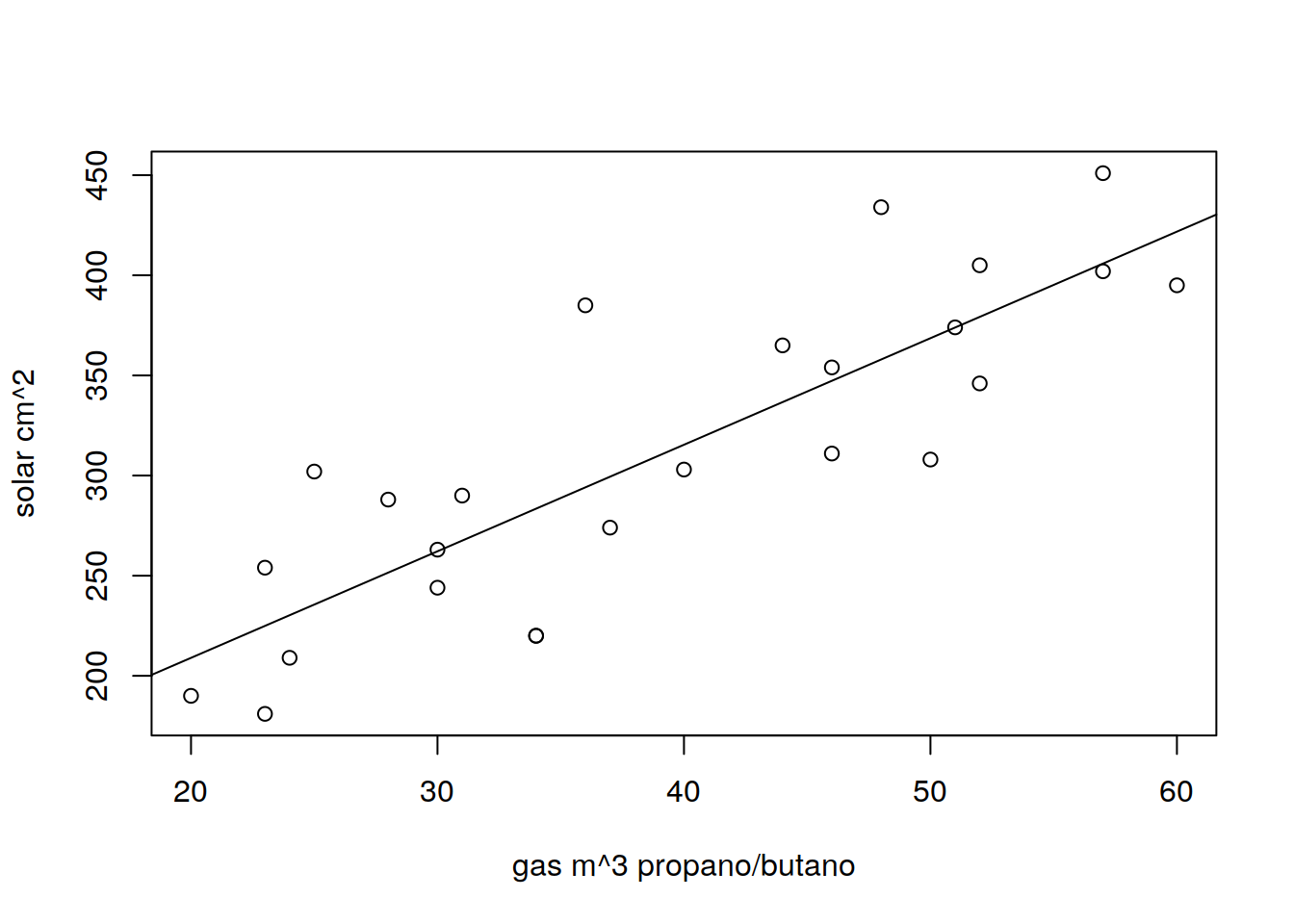
5.2.6 Predicción
Intentaremos realizar una predicción basada en el modelo construido
nuevas.gases <- data.frame(gas = seq(30, 50))
predict(regresion, nuevas.gases)## 1 2 3 4 5 6 7 8
## 262.1954 267.5161 272.8368 278.1575 283.4781 288.7988 294.1195 299.4402
## 9 10 11 12 13 14 15 16
## 304.7608 310.0815 315.4022 320.7229 326.0435 331.3642 336.6849 342.0056
## 17 18 19 20 21
## 347.3263 352.6469 357.9676 363.2883 368.60905.2.7 Intervalos de confianza
confint(regresion)## 2.5 % 97.5 %
## (Intercept) 41.265155 163.885130
## gas 3.822367 6.8189865.2.8 Extrapolación
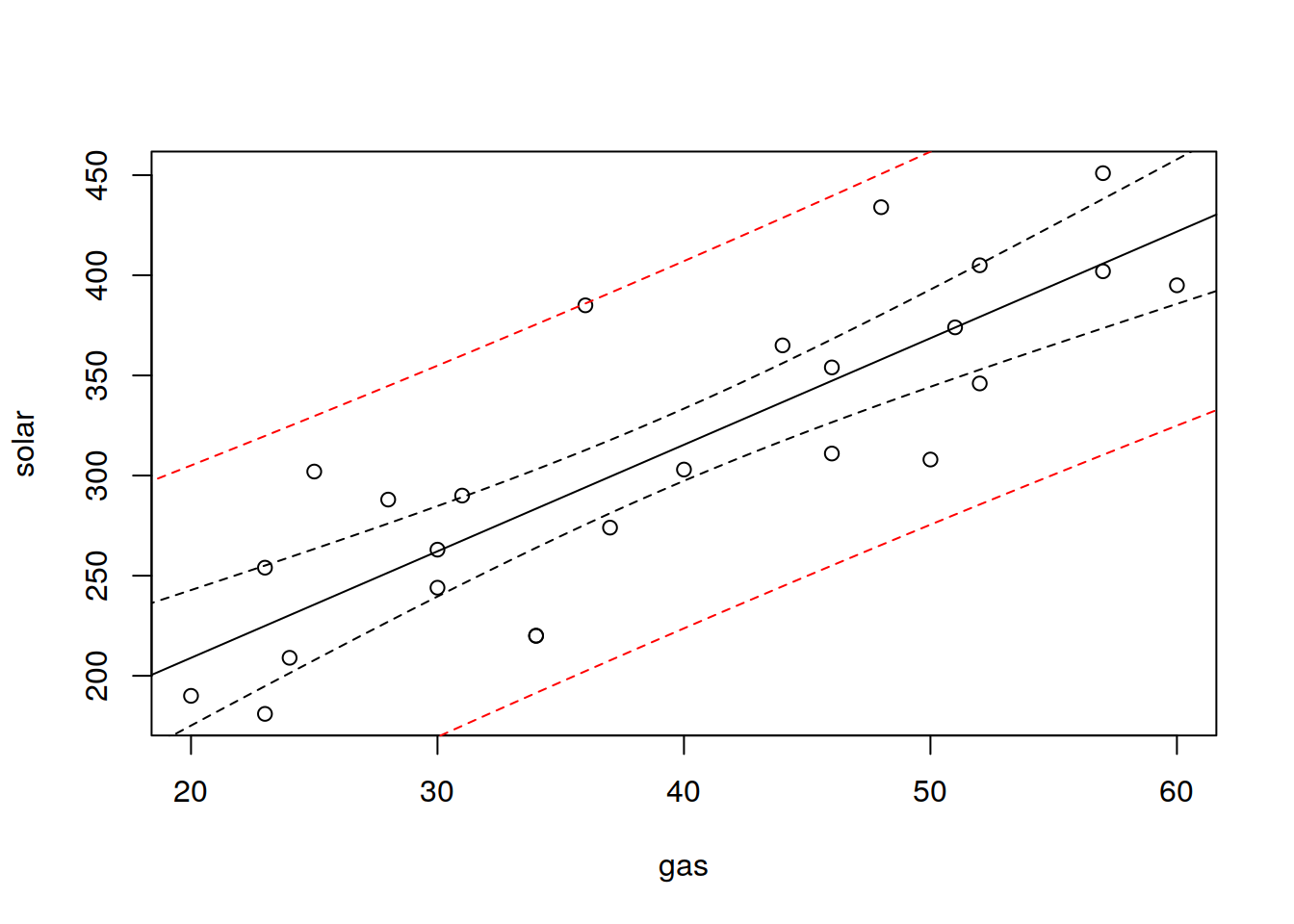
Intervalos de confianza Grafico de dispersion y recta ploteado nuevamente como base
options(tidy=TRUE, width=50)
nuevas.gases <- data.frame(gas = seq(10, 90))
plot(eficiency$gas, eficiency$solar,xlab="gas",ylab= "solar")
abline(regresion)
ic <- predict(regresion, nuevas.gases, interval ="confidence")
lines(nuevas.gases$gas, ic[, 2], lty = 2)
lines(nuevas.gases$gas, ic[, 3], lty = 2)
ic <- predict(regresion, nuevas.gases, interval ="prediction")
lines(nuevas.gases$gas, ic[, 2], lty = 2, col = "red")
lines(nuevas.gases$gas, ic[, 3], lty = 2, col = "red")